- 912
- ۱۴۰۲/۰۲/۰۷ - ۱۱:۳۸
- 553 بازدید
شرح فصل و نکات ویژه: در این فصل به مبحث متابولومیکس پرداخته میشود، و پایگاههای مسیرهای بیوشمیایی و سیگنالیگ معرفی میشوند. شناسایی و مطالعه ی مسیرهای بیوشمیایی هدف اصلی این فصل میباشد. اطلاعات مختلف ژنومیکس به ما در شناسایی مسیرهای ناشناخته و تکمیل آنها کمک میکند. ۲۲۱-متابولومیکس به بررسی متابولیتها، متابولومیکس گفته میشود، به صورت دقیقتر میتوانیم بگوییم تولید، جمع آوری و تجزیه و تحلیل اطلاعات در مورد واکنشهای بیوشیمیایی و متابولیتهای حاصل را تحت عنوان متابولمیکس[…]
شرح فصل و نکات ویژه:
- در این فصل به مبحث متابولومیکس پرداخته میشود، و پایگاههای مسیرهای بیوشمیایی و سیگنالیگ معرفی میشوند.
- شناسایی و مطالعه ی مسیرهای بیوشمیایی هدف اصلی این فصل میباشد.
- اطلاعات مختلف ژنومیکس به ما در شناسایی مسیرهای ناشناخته و تکمیل آنها کمک میکند.
۲۲۱-متابولومیکس
به بررسی متابولیتها، متابولومیکس گفته میشود، به صورت دقیقتر میتوانیم بگوییم تولید، جمع آوری و تجزیه و تحلیل اطلاعات در مورد واکنشهای بیوشیمیایی و متابولیتهای حاصل را تحت عنوان متابولمیکس (Metabolomics ) میشناسند. متابولیتها به عنوان محصولات انتهایی و بینابینی واکنش شیمیایی در هر مسیر سوخت و ساز هستند که به وسیلهی پروتئینها ایجاد میشوند. ژنومیکس، ترانسکریپتومیکس و پروتئومیکس فقط میتوانند عملکرد ژن را نشان دهند ولی نمیتوانند وقوع میزان عملکرد ژن را تعیین کنند. متابولومیکس میزان واقعی عملکرد ژن را نشان میدهد. نقش متابولومیکس در کنترل فنوتیپ موجود زنده نخستین بار توسط گورود با بیماری الکاپتونوریا در نوزاد نشان داده شد. با بررسی فنیل کتونوریا مشخص شد که چطور متابولیتهای بینابینی نظیر افزایش فنیلآلانین میتواند باعث عقبماندگی ذهنی شود و سرنخی برای درمان یا پیشگیری عقبماندگی ذهنی در انسان فراهم کند. در حدود ۲۳۰۰۰ ژن و تعداد بسیار زیادی پروتئین ولی فقط در حدود ۱۰۰۰۰متابولیت در انسان وجود دارد بنابراین به نظر میرسد که متابولومیکس در مقایسه با ژنومیکس و پروتئومیکس راه آسانتری برای دسترسی به مشکلات عملکرد ژن باشد. متابولومیکس همچنین برای تعیین اثرات سمی ماده مفید است و ارزش زیادی در سمشناسی دارد. متابولیتها همچنین برای جستوجوی اثرات مخرب داروها و به کارگیری آنها به عنوان مارکر بیماری مفید هستند. متابولیتهای موجود در مایعات بدن همچون ادرار، بزاق و پلاسما را میتوان به کمک طیفسنجی جرمی، NMR همراه با کروماتوگرافی مایعشناسایی کرد.

تصویر ۱-۱۰: متابولیت تا متابولومیکس.
یکی از بخشهای اصلی دانش سامانههای زیستی مطالعهی مسیرهای بیوشمیایی و استفاده از اطلاعات مختلف ژنومیکس در شناسایی مسیرهای ناشناخته و تکمیل آنها است. از پایگاههایی که به متابولومیکس و ارائه داده در رابطه با PATHWAYها میپردازند میتوان به Reactome، KEGG، CORUM، KEA، PPI Hub Proteins، Bio Carta و Wiki Pathways اشاره کرد.
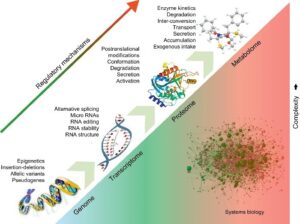
تصویر ۲-۱۰: نمایشی از شبکه ارتباطی پیچیده بین پروتئینهای دخیل در انواع ساختارها و مسیرهای متابولیسمی یک سلول زنده.
۲۲۲-فصل دهم
۱-۱۰ پایگاه KEGG
پایگاه KEGG (Kyoto Encyclopedia of Genes and Genome) در سال ۱۹۹۵ همراه پروژه ژنوم انسانی در ژاپن شروع به کار کرد.این پایگاه به آدرس www.genome.jp/kegg در دسترس میباشد. هدف اولیه این پایگاه سامانمند نمودن اطلاعات موجود در مورد ارتباط بین ماکرومولکولهای زیستی به ویژه مسیرهای بیوشیمیایی، مسیرهای تنظیمی و فرآیندهای زیستی بود. در همان زمان KEGG از شناسنامههای ژنی (برای همه ی موجوداتی که توالی یابی شده بودند) پشتیبانی میکرد و اطلاعات مربوط به هر کدام از واحدهای عملکردی در مسیرهای بیوشیمایی را به شناسنامه مربوطه ارتباطی داد. ضمن این که KEGG اطلاعات مربوط به ترکیبات شیمیایی مورد استفاده در سلولهای زنده را نیز به صورت دادههای دستهبندی شده در میآورد، اطلاعات مربوط به هر یک از آنها را در مسیری که استفاده میشدند ارتباط داد. هدف نهایی KEGG استفاده از ابزارهای بیوانفورماتیکی به منظور بازسازی و پیشبینی عملکرد ژنها و محصولات آنها در مسیرهای سلولی است. در حال حاضر، KEGG به عنوان پایگاهی از دادههای سامانههای زیستی، بسیاری از مسیرهای بیوشیمیایی و تعدادی از مسیرهای تظیمی و رکوردهای فراوانی از ژنها، آنزیمها و سوبستراهای آنها را به طور مستقیم یا با لینک دادن پوشش میدهد.
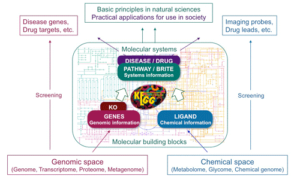
تصویر ۳-۱۰: طرحی از دادههای تشکیل دهنده KEGG و نحوه استفاده از آنها در مدل سازی مسیرهای بیوشیمیایی و سامانههای زیستی.
کاربر بعد از ورود به پایگاه KEGG میتواند با انتخاب KEGG2 به پایگاه اصلی دسترسی پیدا کند و در آن جستوجوی خود را انجام دهد. در این پایگاه دستهبندیهای مختلفی وجود دارد که میتواند برای پیدا کردن بخش مورد نظر بسیار مفید باشد.
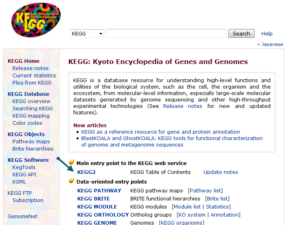
تصویر ۴-۱۰: نمایی از پایگاه KEGG. لینک ورود به KEGG2 با فلش مشخص شده است.
KEGGدارای چندین نوع داده است. تقسیمبندی دادههای موجود در KEGG و محتوی اطلاعاتی هر یک از آنها در جدول زیر آمده است و این اطلاعات دارای اتصالهایی به همدیگر و به پایگاههای موجود از طریق DBGET/LinkDB هستند.
۲۲۳-متابولومیکس
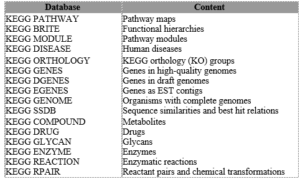
تصویر ۵-۱۰: بخشهای مختلف KEGG.
دادههای این پایگاه به اشکال مختلفی دستهبندی شدهاند. نمایش دادههای KEGG در هر جای این پایگاه با جستوجو یک کلید واژه امکانپذیر است و همچنین از شماره EC ، شماره دسترسی ترکیبات شیمیایی و شماره دسترسی شناسای ژنها میتوان برای جستوجوی مسیرهای KEGG نیز استفاده کرد.
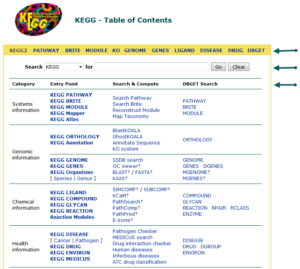
تصویر ۶-۱۰: کاربر بعد از ورود به KEGG2 میتواند از طریق منوی زرد رنگ بالای صفحه به بخشهای مختلف مراجعه کند و یا از طریق قسمت جستوجو کلید واژه خود را جستوجو کند.
بزرگترین مزیت در KEGG داشتن توانایی تجزیه و تحلیلی است که به تصمیمگیری منطقی کمک کند. با داشتن فهرستی از ECهای مربوط به آنزیمها که در کاتالوگهای ژنی موجودات وجود دارد، KEGG به طور خود کار مسیرهای متابولیسمی ویژه هر موجود را با استفاده از جفت کردن آنزیمها با طرح کلی که دارد، تولید میکند. در نهایت
۲۲۴-فصل دهم
از ارتباطاتی که در اثر رسم این مسیرها بین ژنها به وجود میآید برای ارزیابی صحت ثبت عملکرد آنزیمها در کاتالوگهای ژنی استفاده میشود.
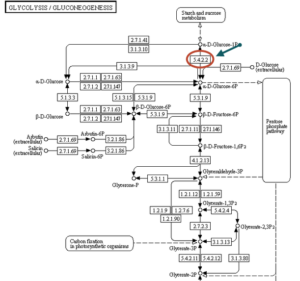
تصویر ۷-۱۰: یک نمونه مسیر متابولیسمی. آنزیمها با کدهای مخصوص مشخص شدهاند. با کلیک روی هر کدام از کدها اطلاعات دقیقی از آنزیم ارائه میشود.
تمام آنزیمهایی که در مسیرهای مختلف در پایگاه KEGG به نمایش گذاشته میشوند به یک صفحه مجزا لینک هستند که در آن صفحه توضیحات کاملی در مورد آنزیم و خصوصیات آن وجود دارد. شناسه مخصوصKEGG مانند C00002 که برای ATP است دارای ۵ رقم و یک پیشوند حرفی است. حرف K برای اورتولوژی KEGG ، حرف C برای ترکیبات، حرف G برای گلیکانها، حرف R برای واکنشها و حرف A برای واکنشهای جفت به کار میروند. این عدد همچنین میتواند با حروف بین ۴-۲ حرفی پیشوند بخورد که نشان دهنده نام موجود و تعدادی رمزهای محدود به مسیرهای متابولیسمی که شامل
ko، rn، map و ot میشوند.
KEGG دارای بخشهای متنوع دیگری نیز میباشد که به راحتی قابل جستوجو میباشند. از مهمترین بخشهای KEGG میتوان به بخشهای زیر اشاره کرد:
۲۲۵-متابولومیکس
P جدول ژنهای اورتولوگ
این جدول را نوع دیگری از نمایش نقشههای بیوشیمیایی میتوان به حساب آورد. با این تفاوت که اطلاعات موجود در این جدول جنبه مقایسه ای دارند. به این صورت که ژنهای حفظ شده و مشترک در مسیرهای بیوشیمیایی موجودات مختلف در این جدول نشان داده میشوند. از این جدول میتوان برای پیشبینی عملکردی پروتئینها بهره برد.
P اطلسهای متابولیسمی و نقشههای ژنومی
این نقشهها به منظور کمک به درک اطلاعات مربوط به جایگاه ژنها مانند ساختار اپرانها و ارتباط آنها با مسیرهای بیوشمیایی به کار میروند. این نقشهها مسیرهای بیوشیمیایی کلی و مسیرهای متابولیکی شناخته شده در سرطانها را در اختیار ما قرار میدهند.
P پایگاه لیگاندهایKEGG
این بخش شامل اطلاعات در مورد لیگاندها،کوفاکتورها، سوبستراها و واکنش آنزیمی مرتبط است. اطلاعات این بخش از اطلاعات موجود در مورد واکنشهای آنزیمی، مسیرهای بیوشیمیایی در گیر در جذب داروها، ترکیبات شیمیایی و واکنشهای بیوشیمیایی جمع آوری و طبقهبندی شدهاند.
۲-۱۰ سایر پایگاههای فعال در زمینه مسیرهای متابولیسمی
۱-۲-۱۰ مسیرهای متابولیمسی Roche
این پایگاه به آدرس http://biochemical-pathways.com توسط Rocheایجاد شده است و یکی از نقشههای جامع متابولیسمی میباشد که به صورت آنلاین ارائه شده است و شامل دو بخش به نامهای Metabolic pathways و
Cellular and Molecular Processes میباشد. این پایگاه به کاربران این امکان را میدهد که با استفاده از کلمات کلیدی به جستوجو بپردازند.
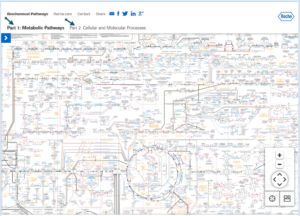
تصویر ۸-۱۰: تصویری از مسیرهای متابولیمسی Roche. از طریق دو محلی که بالای تصویر با فلش مشخص شدهاند کاربران میتوانند به نقشه مسیرهای متابولیسمی و نقشه عملکردهای مولکولی دست پیدا کنند.
۲-۲-۱۰ پایگاه ENZYME
این پایگاه با آدرس http://enzyme.expasy.org فعالیت خود را معطوف به جمع آوری و ارائه اطلاعات در زمینه آنزیمها کرده است. در پایگاه ENZYME میتوان با استفاده از اطلاعاتی همچون شمارهیEC ، کلاس آنزیمی، توضیحات یا نامهای آنزیم، ترکیبات شیمیایی وکوفاکتورها جستوجو را انجام داد.
۲۲۶-فصل دهم
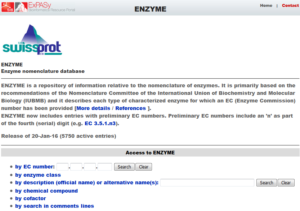
تصویر ۹-۱۰: پایگاه ENZYME.
از دیگر پایگاههای فعال در زمینه مسیرهای متابولیکی میتوان به WikiPathways، REACTOME و BioCarta اشاره کرد که هر کدام از جنبههای خاصی به جمع آوری و انتشار مسیرهای متابولیسمی میپردازند. پایگاه PPI Hub به جمع آوری و انتشار دادههای اینترکشن بین پروتئینها میپردازد.
تصویر ۱۰-۱۰: پایگاه WikiPathways.
۳-۲-۱۰ پایگاه اطلاعاتی مولکولهای شیمیایی:
بانک اطلاعاتی Mass Bank بانک مناسبی برای مطالعه ترکیبات آلی و طیف جرمی مولکولهای شیمیایی است. در این بانک میتوان ترکیبات مختلف شیمیایی را براساس طیف جرمی آنها مقایسه کردکه این کار یک روش مفید برای ترکیبات شیمیایی ناشناخته میباشد. پایگاه مفید دیگر به نام Pubchem در NCBI قرار دارد که یک پایگاه اطلاعاتی
۲۲۷-متابولومیکس
مولکولهای شیمیایی است و شامل سه بخش به نامهای Pubchem Substance، Pubchem Compound و Pubchem BioAssoy میباشد که در زیر شرح داده میشوند.
الف- Pubchem Substance ¬ حدود۶۷ میلیون رکورد دارد.
– در این بانک ساختار شیمیایی مولکولها، توضیحات، لینکهای مرتبط موجود میباشد.
– شناسه این پایگاه SID است.
ب- Pubchem Compound ¬ حدود ۲۶ میلیون رکورد دارد.
– ساختارهای این بانک خوشهبندی شدهاند.
– در اینجا میتوان براساس وزن مولکولی مواد را جستوجو کرد.
– این بانک اطلاعات ساختار و فعالیت را میدهد.
– شناسه این پایگاه CID است.
ج- Pubchem BioAssoy ¬ حدود ۲۵۰۰رکورد دارد.
– در اینجا میتوان فعالیتهای زیستی مولکولهای شیمیایی را مشاهده کرد.
– مثلا شرایط لازم برای فعالیت یک ماده شمیایی را مشخص میکند.
– شناسه این بانک AID است.
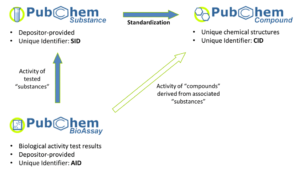
تصویر ۱۱-۱۰: سه بخش اصلی Pubchem در NCBI.