- 745
- ۱۴۰۲/۰۲/۰۶ - ۱۰:۵۴
- 1,396 بازدید
شرح فصل و نکات ویژه: در این فصل به مفاهیم پایهای و کاربردی در رابطه با انواع همردیفیها میپردازیم. همردیفی یا الایمنت کردن دو یا چند توالی با اهداف مختلفی در بیوانفورماتیک انجام میشود. یکی از چالشهای بسیار مهم در بیوانفورماتیک همردیفی توالیها میباشد. انواع BLAST و کاربردهای آن در این فصل شرح داده میشوند. ۱۱۴-فصل ششم بررسی و مقایسه توالیهای ژنتیکی یا توالیهای پروتئینی کمک فراوانی به فرضیه تکامل میکند. به عنوان مثال، میتوان با استفاده[…]
شرح فصل و نکات ویژه:
- در این فصل به مفاهیم پایهای و کاربردی در رابطه با انواع همردیفیها میپردازیم.
- همردیفی یا الایمنت کردن دو یا چند توالی با اهداف مختلفی در بیوانفورماتیک انجام میشود.
- یکی از چالشهای بسیار مهم در بیوانفورماتیک همردیفی توالیها میباشد.
- انواع BLAST و کاربردهای آن در این فصل شرح داده میشوند.
۱۱۴-فصل ششم
بررسی و مقایسه توالیهای ژنتیکی یا توالیهای پروتئینی کمک فراوانی به فرضیه تکامل میکند. به عنوان مثال، میتوان با استفاده از نرم افزار BLAST توالی یک ژن خاص را با میلیونها توالی ژنی موجود مقایسه کرد و از این طریق پی به نیای ژنتیکی بسیاری از ژنها برد. بیوانفورماتیک ابزارهای زیادی برای مطالعه بسیاری از سؤالات مربوط به حوزه بیولوژی مانند پیبردن به شباهت دو ژن خاص با عملکردهای مشابه، در اختیار محققین قرار داده است که عبارتند از تعداد زیادی پایگاه دادهی با ارزش که حاوی اطلاعات ژنها و پروتئینهای بیان شده هستند که از بافتها مشتق شدهاند و نیز نرم افزارهایی برای تحلیل این توالیها، امروزه میلیونها گونه زنده وجود دارد که میتوان آنها را در سه شاخه اصلی باکتریها، آرکیها و یوکاریوتها گروه بندی کرد. پایگاه دادههای مربوط به توالیهای مولکولی هم اکنون توالیهای DNAی بیش از یکصد هزار ارگانیزم مختلف را نگهداری میکنند. ژنوم چند صد ارگانیزم به صورت کامل تعیین توالی شده که از طریق این پایگاههای دادهی نوکلئوتیدی در دسترس است. و حال تجزیه و تحلیل این دادهها و مقایسه آنها با یکدیگر و همچنین گاهی جستوجوی یک توالی در یک بانک یک چالش بزرگ برای کاربر میباشد.
۱-۶ همولوژی و تشابه
تشخیص رابطه تکاملی بین توالیها به مشخص کردن فعالیت توالیهای ناشناخته کمک میکند. انطباق توالیها را میتوان به عنوان اساس پیشگویی ساختار و عملکرد توالیهای ناشناخته مورد استفاده قرار داد. وقتی دو توالی از یک منشا تکاملی مشترک ناشی شده باشند گفته میشود که رابطه “همولوگ” و یا “همولوژی” دارند. اصطلاح مرتبط اما متفاوت دیگر “تشابه” است که درصد باقیماندههای انطباق یافته ای که از نظر خواص فیزیکو شیمیایی مثل اندازه، بار و آبگریزی مشابه هستند را نشان میدهد. همولوژی توالی استنتاج و یا نتیجه گیری درباره داشتن یک رابطه اجدادی مشترک است که از مقایسه تشابه، وقتی که دو توالی شباهت بالایی را نشان میدهند، به دست می آید. از طرف دیگر تشابه یک نتیجه مستقیم از مشاهده انطباق توالیها است. به طور کلی اگر سطح تشابه دو توالی به اندازه کافی بالا باشد میتوان رابطه اجدادی مشترک را نتیجه گیری کرد.
اگر دو توالی در طول کاملشان با هم انطباق داده شوند و ۱۰۰ باقیمانده داشته و یکسانی ۳۰درصد نشان دهند میتوان با اطمینان زیاد به عنوان همولوگ نزدیک در نظر گرفت که به این مقدار “ناحیه امن” اطلاق میشود. اگر یکسانی بین ۲۰ تا ۳۰ درصد باشد تعیین رابطه هومولوژی با قطعیت کمتری امکان دارد که به این مقدار “ناحیه سایه روشن” اطلاق میشود. در یکسانی کمتر از ۲۰درصد جایی که اکثر توالیهای غیر مرتبط قرار دارند، رابطه هومولوزی را نمیتوان با اطمینان تعریف کرد و بنابراین “ناحیه تاریک” در نظر گرفته میشود. باید تاکید کرد که مقدار درصد یکسانی یک راهنمای تجربی برای تعیین هومولوژی فراهم میکند.
نکته: هومولوژی یک رابطه دوطرفه است، اما تشابه یک خاصیت قابل اندازه گیری و قابل تعیین میباشد.

تشابه توالی در برار یکسانی توالی:
تشابه توالی و یکسانی توالی برای توالیهای نوکلئوتیدی هم معنی هستند. برای توالیهای پروتئینی این دو اصطلاح بسیار متفاوتند. در انطباق توالی پروتئینی، یکسانی توالی به درصد اسیدهای آمینه یکسان بین دو توالی انطباق یافته اطلاق میشود. تشابه به درصد اسیدهای آمینه انطباق یافته ای که ویژگیهای فیزیکوشیمیایی مشابه داشته و میتوانند به سادگی با یکدیگر جایگزین شوند اطلاق میشود.
فرمول محاسبه درصد تشابه:
در این فرمول S درصد تشابه توالی، LS تعداد باقیماندههای انطباق یافته با خواص مشابه، La و Lb طول کلی هرکدام از توالیها است.
فرمول محاسبه درصد یکسانی:
![]()
در فرمول فوق Li تعداد باقی ماندههای یکسان انطباق یافته است.
۱۱۵-هم ردیفی توالی ها
ارتولوگ، پارالوگ، گزنولوگ:
- ارتولوگ، همولوگهایی هستند که به وسیله ی فرایند گونهزایی به وجود آمده اند. در واقع آنها دارای ژنهایی حاصل از یک جد مشترک هستند، که عملکرد مشابهی دارند.
- پارالوگ، همولوگهایی هستند که به وسیله مضاعف شدن ژن به وجود آمده اند. آنها از یک ژن اجدادی مشترک که در یک موجود مضاعف و سپس منشعب شده به وجود آمدهاند ممکن است از نظر عملکردی متفاوت از همدیگر عمل کنند.
- گزنولوگها، همولوگهای حاصل از انتقال افقی ژن بین دو موجود میباشند.
تکامل همگرا و واگرا
- تکامل همگرا: تکاملی که در دو گونه ی متفاوت یک سری شباهتهای فنوتیپی(ظاهری) میبینیم که میتواند دلایل محیطی و یا دلایل دیگری داشته باشد، مانند والها که شباهت زیادی به ماهیها دارند.
- تکامل واگرا: تکاملی که در آن جاندارانی که از لحاظ ژنتیکی به هم نزدیک هستند، تفاوت ظاهری داشته باشند. برای مثال تعدادی از موجودات به جای هموگلوبین از هموسیانین که دارای مس میباشد استفاده میکنند.
کدهای اسید نوکلئیک و اسیدآمینهها
پیش از شروع بحث همردیفیها لازم است با کدهای مربوط با توالی اسید نوکلئیک و اسیدآمینهها آشنا شوید. جدول ۱-۶ کدهای مربوط به اسید نوکلئیکها را نمایش میدهدهمانطور که در جدول میبینید کدهای دیگری نیز به غیر از چهار کد اصلی در این جدول وجود دارند و کاربرد این کدها زمانی میباشد که یک توالی اسیدآمینه را میخواهیم به توالی اسید نوکلئیک ترجمه کنیم. هر اسیدآمینه یک نام و یک نماد سه حرفی و یک کد یک حرفی دارد، همچنین کدهای مختلف DNA میتواند اسیدآمینههای مشترکی را کد کنند که درتصویر ۱-۶ نمایی از زیر کدهای سه حرفی مربوط به اسیدآمینهها نمایش داده شده است.
جدول ۱-۶: کدهای مربوط به اسید نوکلئیکها.

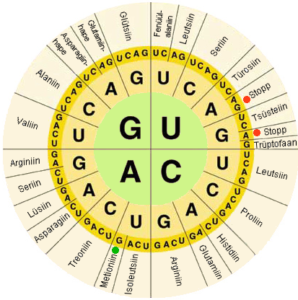
تصویر ۱-۶: کدهای سه حرفی اسیدهای آمینه. همانطور که در تصویر مشاهده میکنید نوکلئوتیدهای سوم متغیرترین کدها در هر اسیدآمینه هستند.
۱۱۶-فصل ششم
۲-۶ ابزارهای مقایسه ژنومها
یکی از ابزاهای مقایسه ژنوم BLAST میباشد، همان طور که در بخشهای بعدی خواهید دید برای مقایسه دو توالی (همردیفی دوگانه) به کار میرود، MUMer نیز برای مقایسه دو ژنوم بکار میرود. این الگوریتم توسط گروه دکتر استیون سالزبرگ نوشته شده است و از طریق پایگاه TIGR آزدانه قابل دسترسی است. MUM توالی است که تنها یکبار در هر دو ژنوم حضور می یابد و بخشی از توالی ژنومی دیگر نیست. Mismathها همواره در کنار این توالیها وجود دارند.

تصویر ۲-۶: نمایی از همردیفی دو توالی.
MUMها براساس موقعیت شان در ژنوم A مرتب می شوند. سپس جهت MUMها در ژنوم B و نحوه matching آن با ژنوم A درنظر گرفته میشود. با استفاده از یک الگوریتم مناسب موقعیت بلندترین MUM در نظر گرفته میشود و همردیفی گلوبال روی آنها انجام میشود.
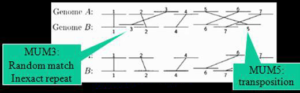
تصویر ۳-۶: نمایش همردیفی MUMها.
در الگوریتم MUMer فرض بر این است که توالیهای دو موجود به یکدیگر نزدیک بوده به همین دلیل مقایسه میلیونها باز به سرعت قابل انجام است. خروجیهای این برنامه عبارتنداز: همردیفی کلیه بازهای موجود در دو توالی، مشخص کردن بخشهای کاملا یکسان و متفاوت در ژنومها، مشخص کردن موقعیت SNPها، تداخلهای بزرگ، تکرارهای معنی دار، معکوس شدگیها و Tandem repeatها. مراحل اجرای الگوریتم MUMer برای مقایسه دو ژنوم به این صورت است که ابتدا همردیفی هر دو ژنوم و مشخص کردن بخشهای کاملا match صورت میگیرد و در مرحله بعد مشخص کردن gapها و سپس SNPها مشخص میشوند.
۳-۶ پایگاههای مقایسهای ژنومها
به علت این که پایگاههای مقایسهای ژنوم در حال توسعه بوده و در عین حال حاوی اطلاعات بسیار زیادی هستند به معرفی کوتاه تعدادی از آنها در اینجا بسنده میکنیم.
۱۱۷-هم ردیفی توالی ها
COG: رده بندی فیلوژنتیکی پروتئینهای رمز شونده در ژنوم موجودات مختلف در این پایگاه یافت میشود. آدرس دسترسی به این پایگاه به آدرس www.ncbi.nlm.nih.gov/COG میباشد و با استفاده از نام پروتئین و یا متن این پایگاه را مورد جستوجو قرار دهید.
Genome analysis: مقایسه دوتایی توالیهای ژنومها با استفاده از نرم افزار BLASTZ برای جستوجوی همولوگهای پروتئینی را انجام میدهد. آدرس دسترسی به این پایگاه www.ncbi.nlm.nih.gov/sutils/geneplot.cgi میباشد کاربر با مراجعه به این پایگاه میتواند در جعبههای جستوجو نام دو موجودی را که مورد مقایسه هستند را وارد کند.
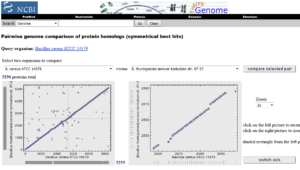
تصویر ۴-۶: نمایی از یک مقایسه دوتایی توالیهای کامل ژنوم دو موجود.
Ensembl: یکی از بهترین پایگاهها برای به دست آوردن اطلاعات مقایسهای بین ژنومها به طور گرافیکی است. پس از رجوع به این پایگاه به آدرسwww.ensembl.org به اطلاعات ارگانیسم مورد نظر خود وارد شوید و میتوانید با کلیک روی گزینه View Syntenic regions، مقایسهای میان کروموزومهای ارگانیسم موجود با سایر ارگانیسمهایی که میتوانید انتخاب کنید انجام دهید.
۱۱۸-فصل ششم
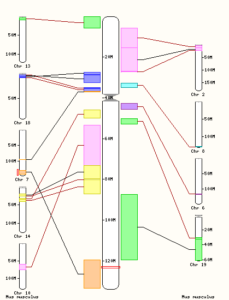
تصویر ۵-۶: همردیفی کروموزوم ۱۰ انسان با کروموزومهای موش. همانطور که مشاهده میکنید ۹ عدد از کروموزومهای موش با کروموزوم ۱۰ انسان به صورت بخشی هم پوشانی دارند.
UCSC: به طور مشابهی میتوان تصاویر گرافیکی از مقایسه بین کروموزومی (syntenic) دو موجود را در پایگاه UCSC داشت. پس از ورود به به ادرس genome.ucsc.edu به اطلاعات موجود مورد نظر خود وارد شوید. سپس در قسمت Comparative Genomics انتخابهای خود را صورت دهید. سپس روی دکمه Refersh کلیک کنید. گرافیک مقایسهای ظاهر میشود.
۴-۶ مقایسه دو توالی
در دهه ۸۰، یک محقق هیچ برنامه رایانهای برای این که بتواند بین تعدادی توالی مشابه توالی را به توالی خود پیدا کند نداشت. بنابراین زبده ترین دانشمندان ان روزگار نیز مجبور بودند این کار را به صورت دستی انجام دهند. به طور مثال، اگر قرار بود از بین سه توالی زیر مشابه ترین توالی را به توالی خود انتخاب میکرد. باید تک تک توالیها را با توالی الگو مقایسه میکرد و میزان شباهتها را در هر مقایسه به دست میآورد. امروزه به این همردیفی دوگانه (Pairwise Alignment) میگویند.

۱۱۹-هم ردیفی توالی ها
سادهترین راه برای مقایسه کردن دو توالی این است که هر بار دو توالی را در زیر هم قرار دهیم و یک به یک بازها را با هم مقایسه کنیم تا شبیه ترین توالی را پیدا کنیم (شکلهای A تا D در تصویر ۶-۶). ولی سوالی که پیش میآید این است که چگونه و با چه معیاری دو توالی مشابه تر را انتخاب میکنیم؟ در این جاست که بحث امتیازدهی (Scoring) مطرح میشود. به عنوان مثال، ساده ترین نوع امتیاز دهی این گونه میتواند باشد که اگر دو بازی که زیر هم قرار میگیرند یکسان باشند، امتیاز یک و اگر همسان نباشند، امتیاز صفر داده شود. با این روش میتوان مشابه ترین توالی و درجه شباهت سایر توالیها را با توالی الگو به دست آورد. حال میتوانیم توالیهای داده شده را با توالی الگو با همین روش همردیفی دوگانه کنیم. به نظر میرسد مورد C که امتیاز ۹ گرفته است، همسانی بیشتری با توالی ما دارد.

تصویر ۶-۶: نمایش امتیاز همردیفی سه توالی متفاوت (سطرهای پایین) با یک توالی یکسان (سطرهای بالا).
در همردیفی دوگانه سوال این است که دو توالی چقدر به هم شبیه هستند. زمانی که ما برای تعیین میزان همسانی از امتیاز دهی و عدد استفاده میکنیم. در واقع از روشهای ریاضی برای حل مسئله ی زیستی استفاده میکنیم. از آنجایی که در دنیای زیست شناسی پارامترهای دخیل بسیار زیاد و در بسیاری از موارد ناشناخته هستند، بنابراین برای حل مسئلههای زیستی با استفاده از الگوریتمهای ریاضی و رایانهای، همواره با مشکل عدم تطبیق کامل مدل ریاضی با واقعیت زیستی روبرو هستیم. تفاوت راه حلها و الگوریتمها با هم در این است که جواب کدام یک به واقعیت زیستی که مشاهده میشود نزدیکتر است و آن را بهتر توجیه میکند.
اما همانطور که در تصویر ۷-۶ دیده میشود، این دو توالی را به طریق دیگری هم میتوان همردیف کرد. لذا سوالاتی هنوز باقی است مانند آن که آیا همردیفی دیگری ممکن است؟ کدام همردیفی بهتر است؟ همردیفی بهتر یعنی چه؟ کدام همردیفی گویای اتفاقات زیستی است؟ آیا در همردیفیها روندهای تکاملی قابل ردیابی است؟ تا چه حد؟ و چگونه میتوان همردیفیها در این راستا به کار گرفت؟
اینها سوالات عمیقی است که پایههای اساسی دادهپردازی زیستی را تشکیل میدهند. در این فصل سعی بر آن است که اصول همردیفی تا اندازهای آموزش داده شود تا به توان از آن برای جستوجوی توالیهای مشابه و قضاوت در مورد میزان مشابهت و درک مفهوم خانوادههای ژنی و پروتئینی استفاده نمود.
همانطور که دیدید با قرار دادن توالیها در زیر یکدیگر و امتیازدهی به این نتیجه رسیدیم که همردیفی C شبیهترین همردیفی میباشد. اما اگر به همردیفی E توجه کنیم، میبینیم که اگر ما در توالی ۱ یک گپ ایجاد کنیم بازهم امتیاز ۹ برای همردیفی به دست میآید که این یک نقص به حساب میآید و با این روش نمیتوانیم به بهترین همردیفی اطمینان کامل داشته باشیم. پژوهشگران برای حل مشکلات موجود در همردیفی روشهای مختلفی را پیشنهاد دادند که یکی از آنها روش Dotplot میباشد.
۱۲۰-فصل ششم

تصویر ۷-۶: ایجاد یک گپ (همردیفی E) میتواند نحوه محاسبه امتیاز را تغییر دهد.
۱-۴-۶ روش Dot plot
محققین به عنوان راهی برای شناسایی تمامی همردیفیهای ممکن، روشی گرافیکی به نام دات پلات (dot plot ) را ایجاد کردند. در این روش دو توالی به صورت عمود بر هم روی محور xها و yها در یک صفحه قرار داده میشوند و در هر نقطه ای که شبیه هم باشند عدد یک قرار داده میشود. اگر دو توالی کاملا شبیه باشند در نهایت، از رسم نقاط یک خط اوریب بدون شکستگی را میتوان از ابتدای سمت چپ بالای صفحه به انتهای سمت راست پایین صفحه رسم کرد. همردیفی در واقع مشخص کردن رابطه ی بین نوکلئوتیدهای یک توالی با توالی دیگر است. اگر دو توالی در تصویر ۷-۶ را به صورت دات پلات در آوریم جدول زیر به دست خواهد آمد. اگر دور بیش از دو عدد ۱ به دنبال هم خط بکشیم، منظره زیر ظاهر خواهد شد. حال براساس این خطوط اریب میتوان کلیه همردیفیهای دو گانه را استخراج کرده و به صورت خطی نوشت.
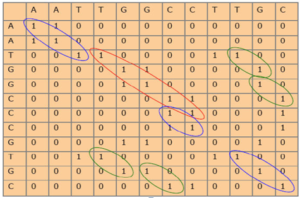
تصویر ۸-۶: نمایش روشDot plo .
در اکثر نمودارهای نقطهای نقاط در همه جای ماتریس پراکنده است که تشخیص انطباق صحیح را مشکل میسازد. برای کاهش نویزها باید از تکنیک فیلتر کردن استفاده کرد، برای مثال میتوان یک رشته را با خودش انطباق داد تا نویزها مشخص شود.
مقایسه همردیفیها
۱۲۱-هم ردیفی توالی ها
در مثالهای پیشین روش امتیاز دهی صفر ویک را میتوان یک نوع الگوریتم به حساب آورد که براساس آن همردیفی با بالاترین امتیاز را به عنوان بهترین همردیفی انتخاب کردیم. ولی در عمل میتوان همردیفیهایی را مثال زد که با وجود امتیاز مساوی یا حتی بالاتر صحیح نبوده و با دانستههای قبلی تطبیق نمیکنند. بنابراین تلاش زیادی برای طراحی و بکارگیری الگوریتمهایی دقیقتر صورت میگیرد که تا هر چه بیشتر دربرگیرنده واقعیات زیستی و اصول حاکم بر حیات باشد.
به طور مثال، در همردیفی توالیهای نوکلئوتیدی میتوان بین امتیازات جایگزینیهای از نوع جانشینی (Substitution) و انتقال (Transition) تفاوت قائل شد. زیرا با توجه به ساختمان دو رشتهایDNA احتمال جایگزینی بازهای پورینی با هم و بازهای پیریمیدینی با هم بیشتر است. در حالی که الگوریتم قبلی تفاوتی را بین این دو حالت قائل نبود. بنابراین جوابهایی هم که با الگوریتم قبلی به دست آمد کمتر به واقعیت نزدیک است. این مشکل در توالیهای پروتئینی به طور جدیتری مطرح است. در این توالیها همه جایگزینیها اشکال ساختاری و عملکردی زیادی ایجاد نمیکنند. به عبارت دیگر، برخی اسید آمینهها خواص فیزیکوشیمیایی مشابهی دارند و میتوانند با حداقل تغییر خواص جایگزین یکدیگر شوند (تصویر ۹-۶).
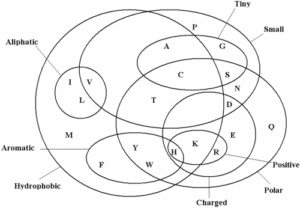
تصویر ۹-۶: خواص فیزیکو شیمیایی اسیدهای آمینه.
نکتهی دیگر این است که در همردیفیهای تصویر ۶-۶ فرض برابر بودن طول توالیهاست. در حالی که در تکامل توالیها هم پدیده ی اضافه شدن را داریم و هم پدیده حذف اتفاق میافتد. بنابراین انتظار میرود در بسیاری از موارد دو توالی را با هم مقایسه کنیم که دارای طول یکسانی نباشند. جمعبندی این مقدمات نشان میدهد میتوان با کمینمودن (امتیازدهی) نتایج همردیفی آنها را باهم مقایسه نمود. البته برای کمی نمودن همردیفیها حداقل دو نوع امتیاز دهی را بایستی منظور کرد.
- امتیاز دهی جایگزینیها
- امتیاز دهی حذف و اضافه شدن توالیها
به این ترتیب، امتیاز هر همردیفی جمع جبری کلیه امتیازات جایگزینیها و حذف یا اضافهها خواهد بود.
۲-۴-۶ امتیازدهی جایگزینیها
با درک این که روش صفر ویک کفایت نمیکند و جایگزینی نوکلئوتیدها یا اسید آمینهها با یکدیگر امتیاز منفی یا مثبت مساوی ندارند. متخصصین امر در پی تهیه جداول امتیازدهی جایگزینیها (Subtitution Scoring Matrices ) بودهاند. بهطوری که تا حد امکان واقعیتهای زیستی را منعکس نماید. برای توالیهای نوکلئوتیدی کار چندان دشوار نیست زیرا
۱۲۲-فصل ششم
هر گونه جایگزینی منجر به جهش میشود که اثر آن در رمزدهی پروتئینها ممکن است مشاهده شود. یعنی در این مولکولها بحث ساختار و عمل چندان مطرح نیست. البته با توجه به ساختمان دو رشتهایDNA متخصصین تکامل زیستی بین جانشینی نوکلئوتید پورین و پیریمیدین و انتقال از پورین به پیریمیدین یا بالعکس تفاوت قائلند. جدول زیر نمونهای از جداول امتیازدهی برای همردیفی دو توالی نوکلئوتیدی را نشان میدهد. در این جدول به طور سادهای کلیه همسانیها امتیاز +۵ و برای غیر جفت شدگی امتیاز -۴ در نظر گرفته شده است.
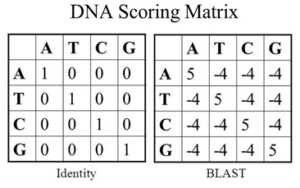
تصویر ۱۰-۶: ماتریس امتیازدهی DNA.
در تهیه جداول امتیازات جایگزینی توالیهای پروتئینی خواص فیزیکوشیمیایی اسیدهای آمینه و تاثیر جایگزینی آنها در ساختار و عمل پروتئینها مطرح است. در گذشته، پژوهشگران به گروهبندی اسیدهای آمینه براساس خواص آنها (تصویر ۹-۶) مراجعه کرده و میزان مشابهت را به صورت توصیفی (و نه عددی) بیان میکردند. در دو دهه اخیر روشهای تهیه جداول امتیازدهی جایگزینی مبتنی بر دادههای موجود در طبیعت بوده است. با فرض بر این که اگر دو اسید آمینه دارای خواص فیزیکوشیمیایی مشابهی هستند بایستی در طول تکامل جایگزینی آنها تحمل شده باشد، پژوهشگران نسبت به جمعاوری توالیها، همردیفی آنها با هم و محاسبه فراوانی جایگزینیها در بین پروتئینهای همخانواده اقدام نمودند. ماتریسهای نمرهدهی اسیدآمینهها ماتریسهای ۲۰ در ۲۰ هستند که طراحی شده اند تا انعکاسی از شانس جایگزینی اسیدآمینه باشند.
یک نوع ماتریس براساس قابلیت جایگزینی کدهای ژنتیکی یا خواص اسیدآمینه است و دیگری از مطالعات تجربی جایگزینی اسیدهای آمینه حاصل شده است. نگرش اول دقت کمتری دارد و ماتریسهای تجربی به واقعیت نزدیکترند. در اولین تلاش، با همردیفی ۱۵۷۲ توالی پروتئینی در ۷۱ درخت از ۳۴ خانواده پروتیئنی گروهبندی شدند. سپس فراوانی جایگزینی یک اسیدآمینه با اسید آمینه دیگر در فرمول زیر بکار گرفته شد:
PAMn= nlog Probability of one substitution/Probablity of occurring by chance*100
در این فرمول یک واحد PAM (Point Accepted Mutation) معادل تغییر ۱ در یک توالی صدتایی از اسیدآمینههاست. دادههای حاصل در جدول PAM ثبت میشود. از آنجا که در طول تکامل ممکن است اسیدآمینه در یک موقعیت چندین بار جایگزین شود، جدول حاصل را چندین بار در خود ضرب میکنند. به طور مثال، برای تهیه جدول PAM250 آن را ۲۵۰ بار در خودش ضرب میکنند (جدول ۲-۶).
۱۲۳-هم ردیفی توالی ها
جدول ۲-۶: ماتریس PAM250.

بعدها جداول دیگری تدوین شدند که از یک نوع اصول پیروی میکردند. با این تفاوت که فراوانی جایگزینیها تنها در مناطق حفاظت شده(Conserved Blocks) برای ساختن جدول وارد محاسبه میشدند. در آن هنگام، ۲۰۰۰ بلوک از ۵۰۰ خانواده پروتئینی در نظر گرفته شد. به طور مشابهی، فرمول زیر بکار رفت:
BLOSUM%=log Probability of substitution in block/Probablity of occurring by chance
این جداول را BLOSUM نامیدند که از اصطلاحBlock Substitution Matrix برگرفته شده است. شماره جدول به نوع بلوک مورد استفاده برای محاسبه فراوانی و احتمال وقوع جایگزینی بستگی دارد. مثلا BLOSUM62 یعنی این جدول برمبنای فراوانی جایگزینیها در بلوکهای حاوی توالیهای با همسانی ۶۲ درصد یا بیشتر تشکیل شده است (جدول ۳-۶).
جدول ۳-۶: ماتریس BLOSUM62.

۱۲۴-فصل ششم

در PAM خانوادههایی که از نظر تکامل ارتباط مشخصی دارند را مورد بررسی قرار میدهند و تغییرات را در ۱۰۰ اسیدآمینه براساس زمان تکامل بررسی میکنند. اما در BLOSUM در Block پروتئینهایی که به نحوی به هم مربوطند را مورد بررسی قرار میدهند. دیگر نگران زمان تکامل لازم برای موتاسیون نیستند. ماتریسها PAM، به استثنای PAM1 از یک مدل تکاملی مشتق شدهاند. در حالی که ماتریسهای BLOSUM براساس مشاهده کاملا مستقیم قرار دارند. بنابراین ماتریسهای BLOSUM ممکن است معنای تکامل کمتری از PAM داشته باشد. ماتریسهای BLOSUM برای جستوجوی پایگاه دادهها و پیدا کردن دمینها در پروتئینها مناسبترند. جدول زیر نمایش میدهد که هرچه PAM بزرگتر و هرچه BLOSUM کوچکتر باشد رابطه تکاملی دورتری را نمایش میدهد.

تصویر۱۱-۶:نمایش رابطه کوچک یا بزرگ بودن ماتریس با نمایش رابطه تکاملی.
سنجش تجربی نشان داده است که ماتریس BLOSUM کارایی بهتری از PAM بر حسب دقت انطباق محلی دارد. این مسئله به احتمال زیاد بدین دلیل است که ماتریسهای BLOSUM از مجموعه دادههای بزرگتری از آنچه که برای ساخت ماتریسهای PAM استفاده شده به دست آمده است. برای جبران این نقص در سیستم PAM، ماتریسهای جدیدتری با استفاده از همان نگرش براساس مجموعه دادههای بیشتر طراحی شدهاند که Gonnet و Johness- Jaylor- thornton را نام برد. امتیاز مثبت در ماتریس BLOSUM بیانگر این است که دو اسیدآمینهای که در حالت طبیعی جایگزین همدیگر میشوند، بیشتر از حالت شانسی است و برعکس علامتسنجی بیانگر این است که دو اسیدآمینهای که در حالت طبیعی جایگزین همدیگر میشوند، کمتر از حالت شانسی است. به عبارت سادهتر، جایگزینهایی که با فراوانی زیاد اتفاق میافتند، امتیاز مثبت و جایگزینیهایی که با فراوانی زیاد اتفاق میافتند، امتیاز مثبت و جایگزینهایی که با فراوانی اتفاق میافتند، امتیاز منفی خواهند داشت.
جدول ۵-۶: کاربرد ماتریسهای متفاوت.

۱۲۵-هم ردیفی توالی ها
همانطور که ذکر شد در تهیه جداول امتیازات جایگزینی توالیهای پروتئینی خواص فیزیکوشیمیایی اسیدهای آمینه و تاثیر جایگزینی آنها در ساختار و عمل پروتئینها مطرح است که این مفهوم در شکل زیر آمده است.
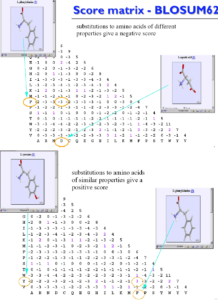
تصویر۱۲-۶: نمایش خواص فیزیکوشیمیایی اسیدهای آمینه در ماتریسBLOSUM62.
ماتریسهای PAM با افزایش واگرایی توالیها، با برونیابی PAM1 از طریق ضرب ماتریسها بهدست میآید. برای مثال PAM80 با هشتاد بار ضرب ماتریس PAM1 بهدست میآید. یک واحد PAM بهعنوان یک درصد تغییرات اسیدآمینه یا یک جهش در یکصد باقیمانده تعریف میشود. افزایش عدد PAM با افزایش واحد PAM و بنابراین فاصله تکاملی توالیهای پروتئین ارتباط دارد.
برای مثال PAM250، که متناظر با ۲۰درصد یکسانی اسیدهای آمینه است، نشاندهنده ۲۵۰ جهش در ۱۰۰ اسیدآمینه است. بنابراین ماتریس PAM250 بهطور معمول برای توالیهای بسیار واگرا استفاده میشود. به این ترتیب، ماتریسهای PAM با شماره کوچکتر برای انطباق دادن توالیهای نزدیک به هم مناسبترند. برعکس سیستم عددگذاری PAM، هر چه عدد BLOSUM کمتر باشد، توالیهای واگراتری حضور دارند.
۱۲۶-فصل ششم
۳-۴-۶ امتیازدهی حذف و اضافه نمودن توالیها
ممکن است جهش به صورت اضافه شدن یا حذفی توالی باشد. بروز این جهشها در توالیها باعث تفاوت در طول توالیها میشود. بنابراین، زمانی که میخواهیم دو توالی را در حالت بهینه همردیف کنیم، نیازمند استفاده از فواصل هستیم. این فواصل بایستی به طریقی در محاسبه امتیاز یک همردیفی لحاظ شوند.
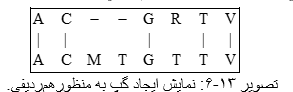
تصویر ۱۳-۶: نمایش ایجاد گپ به منظورهمردیفی.
این که فواصل را در همردیفی چگونه محاسبه کنیم یکی از مبهمترین مسالهها در همردیفی توالیها است. به طور معمول، جریمههایی را که برای فواصل در نظر میگیرند به صورت محلی اعمال میشود. یعنی جریمه استفاده از هر فاصله مستقل از فواصل دیگری است که ممکن است در جاهای دیگری از همردیفی اتفاق بیافتد. در همه برنامهها، برای فواصل دو نوع امتیاز منفی در نظر گرفته میشود.
Gap opening penalty (GOP) جریمه باز کردن توالی:
در طبیعت، هر اضافه نمودن توالی مستلزم صرف انرژی بوده و مورد انتخاب طبیعی قرار خواهد گرفت. بنابراین در الگوریتمها برای همردیفی بهینه توالیها امتیاز منفی نسبتاً بزرگی (مثلا ۱۱-) برای ایجاد فاصله در نظر گرفته میشود.

Gap extension penalty جریمه بسط یک فاصله (GEP):
از این جریمه برای ورود نوکلئوتید یا اسیدآمینه در محلی که قبلا فاصله ایجاد شده است، استفاده میشود. میزان این جریمه از GOP کمتر فرض میشود ولی در تعداد آنها ضرب میشود (مثلا ۱- ضربدر تعداد). زیرا از دید زیستی جایی از توالی که شکافته شده است، استعداد ورود یک یا چند نوکلئوتید را دارد.
۴-۴-۶ انواع همردیفی:
همردیفیها به دو شیوه قابل تقسیمبندی هستند:
الف- از نظر تعداد توالی:
همردیفی دوگانه(Pairwise Alignment): همردیفی تنها دو توالی با یکدیگر در طول کامل آنها یا یک ناحیه خاص
همردیفی چندگانه (Multiple Alignment): همردیفی سه یا چند توالی که از همردیفیهای دو گانه هر جفت آنها نتیجه میشود
ب- از نظر طول
همردیفی محلی (Local Alignment): یافتن و همردیفی بهترین محلهای جور شدن دو توالی.
همردیفی کامل (Global Alignment): یافتن و همردیفی جورشدگی بین طول کامل دو یا چند توالی.
به طور خلاصه، اصول مطرح شده در صفحات قبل در تمامی انواع فوق استفاده میشوند. مثلا همردیفیهای چندگانه از جمع اطلاعات مربوط به کلیه همردیفیهای دوگانه ممکن بین جفت توالی به دست میآید. از آنجا که بیان جزئیات بیشتر باعث دور شدن از مباحث اصلی این درس میشود، در قسمت بعد تنها به آموزش برنامه جستوجوی توالیها در بانکهای اطلاعاتی میپردازیم که بر مبنای همردیفی محلی دوگانه است.
۵-۴-۶ جستوجوی یک توالی:
۱۲۷-هم ردیفی توالی ها
جستوجوی بانکهای اطلاعات توالیها با یک توالی بر مبنای الگوریتمهای نوشته شده برای همردیفی دوگانه صورت میگیرد. جدول زیر مجموعهای از روشهای همردیفیهای دو گانه رانشان میدهد.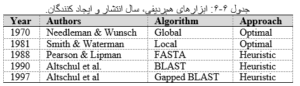
اکنون، در بیشتر پایگاهها از روشBLAST یاBasic Local Alignment Search Tools استفاده میشود که در آن سرعت و دقت با هم در نظر گرفته میشود. BLAST نام یک نرمافزار کاربردی در علوم سلولی و مولکولی و ژنتیک است که مخفف واژگان Basic Local Alignment Search Tool یا ابزار پایهای برای جستوجوی همردیفیهای موضعی است. این ابزار قسمتی از مجموعه اطلاعات کیفی مرکز ملی اطلاعات زیست فناوری است. با این نرم افزار میتوان توالی اسیدهای آمینه در پروتئینها یا توالی نوکلئوتیدها در DNA را با هم مقایسه کرد. این نرم افزار به پژوهشگر اجازه میدهد تا یک توالی را با توالی دیگر یا توالی که در بانک اطلاعاتی وجود دارد، مقایسه کند. شناسایی توالیهای موجود در بانک اطلاعاتی که بیشترین شباهت را با توالی مورد نظر دارد از دیگر قابلیتهای این نرم افزار است. بر حسب نوع توالی انواع مختلفی از BLAST امکانپذیر است. مثلا اگر یک یک ژن ناشناخته در موش که قبلا اطلاعاتی از آن در اختیار نبوده، باید بررسی شود، یک پژوهشگر ترجیح میدهد این توالی را با ژنوم انسان بلاست کند. این نرمافزار در NIH (موسسه ملی بهداشت آمریکا) طراحی شد. BLAST یکی از پرکاربردترین نرمافزارها در بیوانفورماتیک است که با سرعت مطلوب مقایسه مورد نظر را انجام میدهد. سرعت زمانی اهمیت خود را نشان میدهد که با ژنوم کامل روبرو باشیم. پیش از طراحی این نرم افزار مقایسه توالیها بسیار وقتگیر بود به دلیل اینکه BLAST مربوط به یکی از بنیادیترین مسائل بیوانفورماتیک است و سرعت خوبی دارد، یکی از پرکاربردترین نرمافزارهای بیوانفورماتیک به حساب میآید. سرعت، مخصوصا در کاربردهای واقعی روی پایگاههای دادهی بزرگ ژنوم امری حیاتی است.
BLAST از نظر زمانی کارآمدتر از FASTA است، زیرا الگوهای مهمتر در دنباله را مورد جستوجو قرار میدهد. لازم به ذکر است معیارهای BLAST سختگیرانهتر از FASTA است.پیش از ارائه الگوریتمهای سریعی مثل BLAST و FASTA جستوجو در پایگاههای دادهی بزرگ برای دنبالههای پروتئین یا نوکلئیک با استفاده از الگوریتمهای انطباق کامل مثل Smith-Waterman بسیار زمانگیر بود. الگوریتم “اسمیت واترمن” برای انجام دادن یک همترازسازی توالی محلی به کار گرفته میشود و برای مشخص کردن مناطق مشابه بین دو توالی اسید نوکلئیک یا پروتئین استفاده میشود. به جای در نظر گرفتن تمام توالی این الگوریتم سعی میکند که با در نظر گرفتن بخشهای مختلف با همهی طولهای ممکن میزان شباهت را بهینه کند.
این الگوریتم برای اولین بار توسط تمپل اسمیت و مایکل واترمن در سال ۱۹۸۱ ارائه شد؛ که مانند الگوریتم نیدلمن- وانچ با یکسری تفاوتها یک الگوریتم برنامهریزی پویا میباشد. این الگوریتم دارای این خصوصیت است که بر حسب سیستم امتیازدهی (شامل ماتریس جایگزینی و جریمه پرش) که استفاده میشود تضمین میکند که به جواب بهینه برسد. تفاوتی که با الگوریتم نیدلمن- وانچ دارد این است که در ماتریس جایگذاری آن مقادیر منفی با صفر جایگزین میشوند. عمل برگشت به عقب در این الگوریتم از خانهای که مقدار بیشنه را دارد شروع شده و به خانهای که مقدار صفر دارد ختم میشود؛ که این مسیر بیشترین امتیاز همترازسازی محلی را دارد.
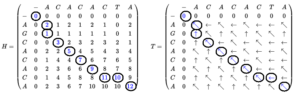
تصویر ۱۴-۱۶: مدل Smith-Waterman
۱۲۸-فصل ششم
۶-۴-۶ BLAST
آنچه در برنامه BLAST انجام میشود پیدا کردن جفت قطعاتی مشابهی از توالی است که امتیاز همردیفی آنها از یک حد آستانه مشخصی بالاتر باشد. این قطعات (HSPs (high-scoring segment pairs نامیده میشوند. برای این کار برنامه BLAST از روش Dynamic Programming استفاده میکند. در این روش برای حل یک مشکل بزرگ، آن را به چند مشکل کوچک تجزیه میکنند. پس از یافتن پاسخ مناسب مشکلات کوچک، آنها را کنار هم چیده و راهی برای پاسخ به مشکل بزرگ پیدا میکنند. با توجه به طول بلند توالیها و امکان جایگزینی و حذف و اضافه در آنها، جستوجوی یک توالی در بین میلیونها رکورد در بانکهای اطلاعاتی نیازمند عملیات سنگینی است که از عهده ابررایانههای امروزی خارج است. در برنامه BLAST از روش dynamic programming برای برون رفت از این معضل استفاده شده است.
سه مرحله اصلی در الگوریتم BLAST وجود دارد که به شرح زیر هستند:
برنامه BLAST توالی مورد نظر (Query ) را به قطعاتی با طول کوتاه یا کلمه (word ) همپوشان تبدیل میکند. معمولا اندازه کلمات برای توالیهای آمینو اسیدی ۳ و برای توالیهای نوکلئوتیدی ۱۱ تنظیم شده است. بنابراین اگر طول توالی را L فرض کنیم، به تعداد L–w+1 قطعه در هر جستوجو تولید میشود. سپس از بین این کلمات آنهایی انتخاب می شوند که در یک همردیفی دوگانه با توالی الگو دارای امتیاز بالایی از یک حد تعیین شده هستند (مانند LSS در تصویر ۱۵-۶). قابل ذکر است که امتیازدهی براساس جداول PAM250 یا BLOSUM62 صورت می گیرد که توسط کاربر قابل تغییر است.

برای هر کدام از جفت توالیهای یافت شده با امتیاز بالا (HSP ) همردیفی توالی از دو طرف کلمه ادامه پیدا میکند تا جایی که همردیفی جدیدی از امتیاز حد آستانه تعیین شدهای کمتر نشود. سپس اضافات توالی یافت شده حذف و همردیفی حاصل برای کاربر ارسال میشود.

۱-۶-۴-۶ انواع BLAST
بنا به نوع توالی مورد نظر و نوع پایگاه مورد جستوجو، برنامههای BLAST طراحی شدهاند که در زیر توضیح داده میشوند. البته برای هریک از این برنامهها نیز زیربرنامههایی که در آن تنظیمات بهینه شده است معرفی شدهاند.
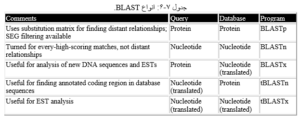
BLASTN
در این نوع BLAST، توالی مورد تقاضای نرم افزار توالی نوکلئوتیدی است و جستوجو در پایگاه توالیهای نوکلئوتیدی انچام میشود. نتیجه جستوجو جفت توالیهای نوکلئوتیدی مشابه است که براساس شاخصهای آماری میزان شباهت و یکسانی آنها نشان داده میشود.
BLASTP
۱۲۹-هم ردیفی توالی ها
در این نوع BLAST، توالی مورد تقاضای نرم افزار توالی پروتئینی است و جستوجو در پایگاه توالیهای پروتئینی انچام میشود. نتیجه جستوجو توالیهای پروئینی مشابه با توالی الگو است که براساس شاخصهای آماری میزان شباهت و یکسانی آنها با توالی الگو نشان داده میشود.
BLASTX
در این نوع BLAST، توالی مورد تقاضای نرم افزار توالی نوکلئوتیدی است که در ۶ قالب خواندنی (ORF) ترجمه شده و به صورت توالی پروتئینی در پایگاه توالیهای پروتئینی جستوجو میشود. نتیجه جستوجو توالیهای مشابه با توالی الگو است که براساس آن میتوانیم به توالی جدید خود قالب خواندنی و عملکرد نسبت بدهیم.
tBLASTN
در این نوع BLAST، توالی مورد تقاضای نرم افزار توالی پروتئینی است و جستوجو در پایگاه توالیهای نوکلئوتیدی انچام میشود که در ۶ قالب خواندنی ترجمه شده است. نتیجه جستوجو توالیهای مشابه با توالی مورد تقاضاست که براساس آن میتوانیم برای توالی پروتئینی خود توالیهای رمز کننده ی آن را شناسایی کنیم.
tBLASTX
در این نوع BLAST، توالی مورد تقاضای نرم افزار توالی نوکلئوتیدی است که در ۶ قالب خواندنی به پروتئین ترجمه میشود ودر پایگاه توالیهای نوکلئوتیدی که آن نیز در ۶ قالب خواندنی به پروتئین ترجمه میشود مورد جستوجو قرار میگیرد. این نوع جستوجو بویژه در مطالعات EST به کار می رود.
به طور معمول در کارهای پژوهشی محقق دارای یک توالی اولیه هست که می خواهد توالیهای مشابه آن را از طریق جستوجوی در بانکهای اطلاعاتی به دست آورد. توالی که قصد بررسی آن را داریم پس از دریافت از بانکهای اطلاعاتی وارد نرم افزار BLAST میکنیم. نرم افزار BLAST توسط سرویس دهندههای مختلفی در دسترس است که یکی از اصلیترین سرویس دهندهها در سایت NCBI در دسترس میباشد و همانطور که در تصویر ۱۸-۶ میبینید یک جایگاه ویژه برای وارد کردن توالی دارد. در تصویر ۱۸-۶ هشت قسمت علامت گذاری شده است که به منظور تنظیم پارامترهای مختلف مورد استفاده قرار میگیرند. این تصویر مربوط به BLAST نوکلئوتید میباشد و به علت شباهت آن به BLAST پروتئین فقط یک تصویر نمایش داده شده است اما در هر قسمت که تفاوتهایی با BLAST پروتئین وجود داشته باشد توضیح داده میشود.
۱۳۰-فصل ششم
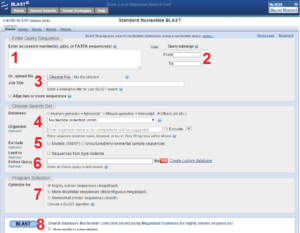
تصویر ۱۸-۶: بخشهای مختلف نرم افزار BLAST.
جایگاه ۱: در این بخش توالی مورد نظر با فرمت FASTAو یا در صورت دانستن شماره دسترسی آن را وارد میکنیم.
جایگاه ۲: در این بخش میتوانیم فقط قسمتی از توالی را مشخص کنیم که قصد داریم مورد بررسی قرار بگیرید. اگر میخواهیم کل توالی که در کادر قبلی وارد کردیم مورد بررسی قرار بگیرید نیاز نیست اینجا اعدادی را مشخص کنیم.
جایگاه ۳: اگر توالی را در جایی از کامپیوترمان ذخیره کرده باشیم میتوانیم در این قسمت آپلود کنیم. همچنین میتوانیم در قسمت job title به جستوجوی خود نام و توضیح کوچکی را اختصاص بدهیم.
جایگاه ۴: این بخش مربوط به نوع پایگاه داده است که میخواهیم توالی ما در آن جستوجو شود. به صورت پیشفرض کلیه پایگاههای مشابه با nr (nonredundent) مورد هدف است.
جایگاه ۵: این بخش مربوط به انتخاب نوع ارگانیسم مورد نظر ما است که گزینهای اختیاری است و در صورتی که ما در موجود خاصی فقط بخواهیم جستوجو شود از این بخش باید استفاده شود.
جایگاه ۶: این بخش مربوط به جستوجوی توالی ما در entrez است که اختیاری میباشد و میتوانیم جستوجو در مورد توالی خود را با کلید واژه محدود کنیم.
جایگاه ۷: در این بخش نوع الگوریتم BLAST را مشخص میکنیم. الگوریتمهای دیگر دارای کاربردهای دیگر میباشد. در جایگاه ۷ اگر تنظیم پارامترهای BLAST نوکلئوتید را انجام میدهید یکی از موارد زیر را میتوانید انتخاب کنید.
Optimize forSomewhat similar sequences (blastn)
Optimize forHighly similar sequences (megablast)
Optimize forMore dissimilar sequences (discontiguous megablast)
اگر در جایگاه ۷ تنظیم پارامترهای BLAST پروتئین را انجام میدهید یکی از موارد زیر را میتوانید انتخاب کنید
blastp (protein-protein BLAST)
PSI-BLAST (Position-Specific Iterated BLAST)
PHI-BLAST (Pattern Hit Initiated BLAST)
DELTA-BLAST (Domain Enhanced Lookup Time Accelerated BLAST)
جایگاه ۸: در انتهای صفحه با کلیک بر روی گزینه BLAST جستوجو آغاز میشود و بعد از لحظاتی صفحه بروز میشود تا نتایج جستوجو نمایش داده شود.
۱۳۱-هم ردیفی توالی ها
PSI-BLAST (Position-Specific Iterated BLAST)
از این نوع BLAST برای یافتن رابطههای دور یک پروتئین استفاده میشود. در این برنامه ابتدا یک لیست از پروتئینها با رابطه نزدیک ساخته میشود و سپس این پروتئین به یک پروفایل سکانس کلی تبدیل میشود که حاوی خلاصه خصوصیات مهم در این دنبالهها میباشد. سپس جستوجو براساس این پروفایل در مقابل پایگاه داده پروتئینی انجام میگیرد و متعاقبا یک گروه بزرگ پروتئین پیدا میشود. این گروه بزرگتر پروتئینی سپس برای ایجاد پروفایل دیگری به کار میرود و این روند در جهت یافتن پروتئینهایی که رابطه بسیار دوری با پروتئین مورد نظر دارند، ادامه مییابد. در نتیجه PSI-BLAST به عنوان حساسترین برنامه BLAST در جهت یافتن فاصلههای دور در ارتباطات تکاملی کاربرد دارد.
PHI-BLAST (Pattern Hit Initiated BLAST)
جستوجو را برای توالیهایی که به طور قابل توجهی مشابه به هر دو توالی مورد نظر ورودی (query) و الگو (Pattern) انجام میدهد. به عبارت دیگر در PHI-BLAST جستوجو براساس ترکیبی از تطبیق الگو (pattern matching) و تطبیق موضعی (local alignment) انجام میشود. در نتیجه با اطلاع از الگوی پروتئینی مربوط به توالی مورد نظر، برنامه PHI-BLAST برای توالی مورد نظر به کار میرود.
تنظیم پارامترهای پیشرفته BLAST
در ناحیه زیر جایگاه ۸ در تصویر ۱۸-۶ پارامترهایی به منظور تنظیمات پیشرفته وجود دارند که در تصویر ۱۹-۶ مشخص شدهاند و در ادامه به شرح این جایگاهها میپردازیم.
جایگاه ۹: با کلیک بر روی گزینه Algorithm parameters قسمت تنظیمات پارامترهای پیشرفته باز میشود و کاربر میتواند پارامترهای عمومی، امتیازدهی و فیلترگزاری را انجام دهد.
جایگاه ۱۰: در این بخش میتوان تعداد توالیهای نمایشی در یک صفحه، پارامترهای مربوط به توالیهای کوتاه، میزان آستانه. اندازه کلمات مورد جستوجو توسط BLAST تنظیم کرد.
در زمان تنظیم پارامترهای پیشرفته BLAST نوکلئوتید به شما اجازه میدهد Word size 16 و تا ۲۵۶ نوکلئوتیدی را انتخاب کنید ولی در زمان تنظیم پارامترهای پیشرفته BLAST پروتئین در این قسمت به شما اجازه میدهد Word size 2 یا ۳ و حتی ۶ اسیدآمینهای را انتخاب کنید و همچنین در BLAST پروتئین امکان انتخاب ماتریسهای PAM و BLOSUM مختلف را دارید. لازم بهذکر است در BLAST پروتئین ماتریکس BLOSUM62 بهصورت پیشفرض انتخاب شده است و کاربر میتواند براساس نوع جستوجوی خود این مقدار را تغییر دهد.
جایگاه ۱۱: این قسمت برای تنظیم پارامترهای امتیاز دهی طراحی شده است. نوع ماتریس امتیازدهی، جریمه فواصل و فرضهای مربوط به نحوه اعمال ماتریسهای امتیازی را میتوان به صورت دستی تنظیم کرد.
جایگاه ۱۲: در این بخش میتوان الگوریتم را برای در نظر نگرفتن نواحی از توالیها که ارزش تکاملی ندارند و یا دارای اشکال و ابهام هستند تنظیم کرد. با انتخاب فیلتر مربوطه بخشهای مورد نظر از توالی در جستوجو لحاظ نمیشوند.
۱۳۲-فصل ششم
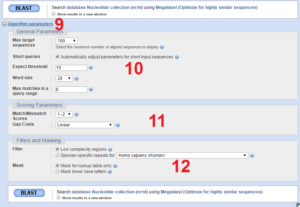
تصویر ۱۹-۶: بخشهای مختلف نرم افزار BLAST، قسمت پارامترهای الگوریتم.
بعد از وارد کردن توالی در جایگاه مربوطه و انتخاب پارامترهای مورد نظر، زمانی که BLAST را اجرا میکنیم صفحه ای باز میشود که اطلاعات مختصری را در مورد توالی ما میدهد و اعلام میکند که جستوجوی ما در حال انجام است و نتایج بعد از چند ثانیه نشان داده خواهند شد. در صورت شلوغ بودن سرور سایت اعلام میکند که جستوجوی خود را در زمانی دیگر دوباره انجام دهیم. صفحهی نتایج شامل چهار بخش است:
بخش اول: شامل توضیحاتی در مورد در مورد الگوریتم BLAST و نویسندگان این الگوریتم و ویرایشهایی است که در گذشته و حال مورد استفاده هستند. در این بخش جستوجوی ما دارای یک ID است که در صورت لزوم (مثلا بروز مشکل و درخواست کمک از مدیر پایگاه) میتوانیم با اینID به جستوجوی خود در NCBI دسترسی داشته باشیم. این بخش توضیحاتی در مورد پایگاه داده ای که ما برای جستوجوی خود انتخاب کرده ایم نیز می دهد.
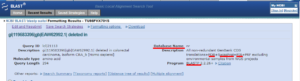
تصویر ۲۰-۶: قسمت اول نتایج BLAST.
بخش دوم: این صفحه نمایشی گرافیکی از نتایج BLAST است به طوری که ۱۰۰ توالی اولی که در جستوجوی BLAST به دست آمده اند به صورت خطوط رنگی نشان داده می شوند هر توالی براساس میزان شباهت خود دارای یک طیف رنگی است. کلید رمز رنگها براساس امتیاز همردیفی در بالای آن آمده است. هر چه قدر جور شدن توالی یافت شده با توالی در حال جستوجو بیشتر باشد با رنگ قرمز و هر چه کمتر باشد با رنگهای رو به مشکی نمایش داده میشود. بنابراین در این قسمت در یک نگاه کلی میتوانیم میزان شباهت را مشاهده کنیم.
۱۳۳-هم ردیفی توالی ها

تصویر ۲۱-۶: قسمت دوم نتایج BLAST.
بخش سوم: در بخش سوم شماره دسترسی (شماره ۱) و نام (شماره ۲) توالیهای بدست آمده فهرست شدهاند. روبروی هر توالی دو عدد هست که اولین عدد امتیاز همردیفی دوگانه (شماره ۳) توالی یافت شده و توالی در حال جستوجو است که کلیه اطلاعات بعدی براساس آنها مرتب میشوند. دومین شاخص، ارزش مورد انتظار یا E-value (شماره ۴) است. (شمارههای ۱ تا ۴ در تصویر ۲۲-۶ علامت گذاری شده اند)

تصویر ۲۲-۶: قسمت سوم نتایج BLAST. (توضیحات در متن).
۱۳۴-قصل ششم
تعریف شاخص E-value به صورت ساده این است که “چه قدر احتمال دارد که توالی جفت شده با توالی الگوی ما به طور تصادفی جفت شده باشد و هیچ رابطه ی معنیداری بین آنها وجود نداشته باشد “این احتمال از رابطه زیر به دست میآید:
طبیعی است که اگر E-Value هر چه به صفر نزدیکتر باشد اطمینان ما به نتیجه بدست آمده بیشتر میشود. نتایج BLAST براساس این دو شاخص مرتب میشوند و بنابراین توالیهایی که در اوایل لیست هستند، توالیهایی هستند که اطمینان ما در شباهت آنها به توالی الگوی مورد نظرمان بیشتر است. بنابراین E-Value نمیتواند مقداری دقیقاً مساوی صفر بگیرد اما میتواند مقدار بزرگتر از ۱۰ داشته باشد همچنین مقدار E-Value به طول توالی بستگی دارد.
بخش چهارم: جزئیات همردیفی تک توالیها با توالی الگوی ما آورده شده است که شامل اطلاعاتی در مورد Score همردیفی میزان شباهت دو توالی و تعداد جایگاههای جفت شده و تعداد فواصل استفاده شده و … است. بخشی از دو توالی که هم ردیف شدهاند در زیر این توضیحات میآید که میتوان به راحتی مناطق مشترک بین دو توالی را مشاهده کرد (تصویر ۲۳-۶).
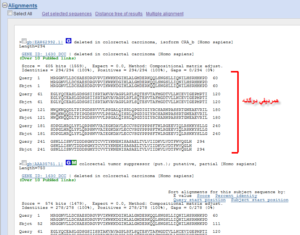
تصویر ۲۳-۶: قسمت چهارم نتایج BLAST.
۲-۶-۴-۶ سایر کاربردهای BLAST
۱۳۵_هم ردیفی توالی ها
کاربرد اصلی BLAST یافتن تشابهات است و فرض ما این است که توالیهای مشابه اغلب از یک توالی اجدادی یکسان مشتق میشوند یعنی اگر توالیها مشابه باشند احتمالا دودمان مشترکی دارند و ساختار یکسان و عملکرد زیستی یکسانی دارند. BLAST توسط ارائه دهندگان متفاوتی در دسترس میباشد که یکی از معروفترین آنها NCBI میباشد. مثلا ما میتوانیم BLASTP را در NCBI و هم در EMBnet استفاده کنیم و البته چون بانکها با هم متفاوت هستند حتما نتایج تاحدودی با هم متفاوت خواهند بود.
NCBI در کنار ارائه BLAST که پیشتر شرح داده شده برای کارهای دیگری هم که نیاز به پیدا کردن توالی میباشد ابزارهای متفاوتی را ارائه میدهد. مثلا cdart BLAST برای پیدا کردن یک توالی خاص در یک پروتئین کاربرد دارد و همچنین GEO BLAST در رابطه با بیان ژنها به ما کمک میکند. با کمک IgBLAST توالیهای ایمونوگلبولین را میتوان بررسی کرد و انواع دیگری BLAST توسطNCBI در دسترس است که در زیر مشاهده میکنید:
- Make specific primers with Primer-BLAST
- Cluster multiple sequences together with their database neighbors using MOLE-BLAST
- Find conserved domains in your sequence (cds)
- Find sequences with similarconserved domain architecture (cdart)
- Search sequences that have gene expression profiles(GEO)
- Searchimmunoglobulins and T cell receptor sequences (IgBLAST)
- Screen sequence for vector contamination(vecscreen)
- Aligntwo (or more) sequences using BLAST (bl2seq)
- Searchprotein or nucleotide targets in PubChem BioAssay
- SearchSRA by experiment
- Constraint Based Protein Multiple Alignment Tool
- Needleman-Wunsch Global Sequence Alignment Tool
- SearchRefSeqGene
- Searchtrace archives
- Search bacterial and fungal rRNA sequences with Targeted Loci BLAST
طراحی پرایمر
Primer BLAST یک ابزار آنلاین میباشد که توسط NCBI در دسترس است و به محققین برای طراحی پرایمر یاری میرساند. کاربر میتواند توالی خود را به نرمافزار ارائه دهد تا نرمافزار یک سری پرایمر مفید پیشنهاد دهد و یا حتی میتوان پرایمری را که توسط ابزار دیگری طراحی کردیم با Primer BLAST مورد بررسی قرار دهیم تا میزان اختصاصیت پرایمر را بررسی کند.
برای طراحی پرایمر ابتدا باید توالی ژن مورد نظر را از بانک توالیها به دست آورد. با توجه به هدف پژوهشی مورد نظر باید محدودهای از توالی را که قرار است تکثیر شود را تعیین کرد و سپس اقدام به طراحی پرایمر نمود. در طراحی پرایمر باید به معیارهای مختلف از قبیل طول پرایمر، درصد GC، دمای (annealing) TM و اختصاصی بودن انتهای توجه داشت. طراحی پرایمر خوب سبب موفقیت در PCR و برعکس طراحی نادرست پرایمر میتواند منجر به تولید کم، و یا عدم تولید محصول مطلوب، تولید محصولات غیراختصاصی و یا تشکیل دایمر پرایمر شود که با تولید محصول اصلی رقابت کرده و سبب کارکرد نامطلوب PCR میشود. امروزه نرمافزارهای مختلفی وجود دارند که طراحی پرایمر را انجام میدهند، اما محقق باید بررسی نهایی را انجام دهد و به نکات خاصی توجه داشته باشد که برخی از این نکات در زیر آورده شدهاند:
۱- طول پرایمر: به طور معمول طول پرایمرها باید ۳۰-۱۸ نوکلئوتید باشد. برای جلوگیری از اتصالات غیراختصاصی پرایمر، طول پرایمر باید حداقل ۱۸ نوکلئوتید باشد. اندازه ۲۲-۱۸ نوکلئوتید، مطلوبترین اندازه برای پرایمر است. همچنین باید از توالیهای بلند نوکلئوتیدی به تعداد چهار نوکلئوتید یا بیشتر خودداری شود.
۲- دمای Tm: بهترین دمای Tm حدوداً بین ۵۰ تا ۶۰ درجه است. محاسبه حدود تقریبی دمای واسرشتی از فرمول Wallace، Tm=2(A+T)+4(G+C) قابل استفاده میباشد (محاسبه عموما برای ۳۰-۱۸ نوکلئوتید قابل اعتماد است). اختلاف Tm بین پرایمرهای رفت و برگشتی باید حداقل باشد بهتر است که این اختلاف کمتر از ۵/۲ درجه باشد.
۳- درصد GC: محتوای GC پرایمرها باید بین ۴۰ تا ۶۰ درصد باشد تا اختصاصیت اتصال آن به ناحیه مورد نظر حفظ شود. بهتر است اختلاف درصد GC پرایمرهای رفت و برگشتی از ۵% بیشتر نباشد.
۴- انتهای و توالی: بهتر است در انتهای پرایمر یکی از نوکلئوتیدهای A یا T قرار گیرد. ولی مطلوب آن است که پرایمر در انتهای خودداری C و یا G باشد تا اتصال محکمی را با DNA الگو برقرار کند. با توجه به اهمیت انتهای، نباید این ناحیه از پرایمر در تشکیل ساختارهای ثانویه مانند سنجاق سر و یا دایمر شرکت کند.
۵- بهتر است نوکلئوتیدهای A, T, G, C توزیع یکسانی داشته باشند.
۶- برای بررسی تشکیل نشدن Hairpinها میتوان از نرمافزارهای مختلف کمک گرفت.
۱۳۶-فصل ششم
۷- برای بررسی تشکیل نشدن dimerها میتوان از نرمافزارهای مختلف کمک گرفت.
۸- برای بررسی تشکیل نشدن loop میتوان از نرمافزارهای مختلف کمک گرفت.
۹- : معمولا وقتی خیلی منفی باشد GC زیاد است.
۱۰- برای اطمینان از این که پرایمر طراحی شده قادر به شناسایی دیگر توالیهای DNA به غیر از ژن هدف نیست، پرایمرها را با برنامه Primer BLAST آنالیز میشوند.
۷-۴-۶ FASTA
بسته نرمافزاری فست ای که هماکنون مورد استفاده قرار میگیرد شامل برنامههایی برای جستجوی پروتئین- پروتئین،
DNA-DNA، پروتئین– DNA ترجمه شده (همراه با تغییرات محتوا) و جستوجوی پپتیدهای آرایش یافته و آرایش نیافته میباشد. نسخههای نهایی فست ای شامل الگوریتمهای جستوجوی ویژهای میباشد که جهت تصحیح خطاهای تغییر محتوا، هنگام بررسی توالی داده پروتئین با نوکلئوتید، مورد استفاده قرار میگیرد. علاوه بر این جهت افزایش سرعت روشهای جستوجوی اکتشافی (heurisitic search) بسته نرمافزاری فست ای مجهز به (SSEARCh) ابزاری برای بهینهسازی الگورتیم اسمیت واترمن میباشد. بیشترین تمرکز این بسته نرمافزاری بر روی صحت آمار مشابه میباشد، بنابراین زیستشناسان بهراحتی میتوانند در مورد اینکه یک همترازی بهصورت اتفاقی حاصل شده و یا ممکن است به واسطه همولوژی باشد، اظهار نظر نمایند. فست ای یک توالی نوکلئوتید یا یک رشته آمینو اسید را بهعنوان ورودی دریافت کرده و به کمک همترازسازی محلی توالی دادهی ورودی و توالیهایی که در پایگاه داده هستند، تشابهات توالیهای متعلق به پایگاه دادههای یکسان را پیدا کند. برنامه فست ای از یک روش Heuristic بسیار گسترده پیروی مینماید که سرعت اجرای برنامه را بسیار ارتقاء داده است. روش کار بدین صورت است که برنامه ابتدا یک الگو برای شناخت کلمات در نظر میگیرد سپس بر اساس طول جمله، کلمات متناظر با هم را تفکیک مینماید سپس کلماتی را که دارای بیشترین احتمال تناظر هستند را قبل از اجرای بیشتر یک جستوجوی بهینهسازی زمانگیر با استفاده از الگوریتم Smith- Waterman علامت میزند. در مرحله آخر جستوجو از الگورتیم اسمیت واترمن جهت محاسبهی امتیاز بهینه برای همترازسازی (Alignment) استفاده میشود.
۵-۶ مقایسه چند تایی توالیها (Multiple sequence alignment)
مقایسه چند تایی توالیهاکه MSA نیز نامیده میشود شکل گسترده ای از مقایسه است که در آن چند توالی به دست آمده با تشابههای مناسب با یکدیگر جور میشوند. تحت چنین شرایطی، اغلب نیاز است که تعداد زیادی از مقایسه دوگانه را به یک مقایسه منفرد تبدیل نماییم به گونه ای که موقعیتهایی که از لحاظ تکاملی با هم معادلند در طول تمام توالیها با هم جور شوند. مقایسه چند تایی توالیها اجازه میدهد تا بتوانیم الگوهای محافظت شده توالیها را در اعضای یک خانواده ارزیابی نماییم. به علاوه این ابزار برای اقدامات اولیه جهت آنالیز فیلوژنتیک خانوادهها و پیش بینی ساختار دوم و سوم پروتئین ضروری است.
از لحاظ تئوری امکان استفاده از برنامههای دینامیک برای مقایسه چندین توالی وجود دارداما به علت این که با افزایش تعداد توالیها زمان محاسبه بسیار کند میشود به همین خاطر برای یک مجموعه بیشتر از ده توالی از روشهای دینامیک استفاده نمیکنند و راهکارهای هورستیک استفاده میشود. جور شدن چند تایی توالیها براساس یک تابع نمره دهی خاص صورت میپذیرد. این تابع از تکنیک مجموعه جفتها یا SP استفاده میکند به طوری که مجموع نمرات تمامی جفتهای ممکن در مقایسه چند تایی توالیها براساس یک ماتریکس نمره دهی خاص میباشد.
۱-۵-۶ الگوریتمهای هورستیک(Heurestic algorithms)
در علوم کامپیوتر، هوش مصنوعی و بهینهسازی، الگوریتم جستوجوی کاشف یا هیوریستیک، روشی برای حل مسائلی است که راههای کلاسیک حل آنها بسیار کند میباشند و یا راه حل تقریبی برای مسائلی است که راههای کلاسیک نمیتوانند برای آنها جواب دقیقی پیدا کنند. بیشتر مسائل پیچیده نیازمند ارزیابی تعداد انبوهی از حالتهای ممکن برای تعیین یک جواب دقیق میباشند. زمان لازم برای یافتن یک جواب دقیق اغلب بیشتر از یک طول عمر است. هیوریستیکها با استفاده از روشهای نیازمند ارزیابیهای کمتر و ارائه جوابهایی در محدودیتهای زمانی قابل قبول دارای نقشی اثر بخش در حل چنین مسائلی خواهند بود.
این الگوریتم در سه گروه قرار میگیرد: ۱. مقایسه تکراری (لوپ) ۲. مقایسه مبتنی بر بلوک ۳. مقایسه پیشرونده (progressive)
۱-۱-۵-۶ مقایسه تکراری (لوپ)
راهکار مکرر براساس این ایده است که اگر جوابهای زیر سطح بهینه را به طور مکرر تغییر دهیم میتوان به یک جواب بهینه دست یافت. این روند با یک مقایسه با کیفیت پایین شروع میگردد و سپس این مقایسه را به طور مکرر تکرار مینماید تا پاسخ بهبود یابد و این کار را تا زمانی انجام میدهد که دیگر افزایش بهبودی در نتیجه دیده نشود. PRRN برنامه تحت وب است که از استراتژی تکرار برای مقایسه استفاده میکند. این روش مقایسه چند تایی را از طریق دو مجموعه تکراری انجام میدهد: تکرار داخلی و تکرار خارجی.
۱۳۷-هم ردیفی توالی ها
۲-۱-۵-۶ مقایسه مبتنی بر بلوک یا توالیهای حفاظت شده محدود
استراتژیهای مقایسه شدیدا مبتنی بر مقایسه کامل توالیها هستند و ممکن است قادر نباشند که دمینها و موتیفهای محافظت شده را از بین توالیهای شدیدا واگرا و با طول متفاوت تشخیص دهند. برای این چنین توالیهای واگرا که تنها با هم تشابه منطقه ای دارند بایستی از یک روش مقایسه موضعی استفاده نمود. استراتژی یک بلوک از مقایسه بدون شکاف که در بین تمام توالیها مشترک است منشا میگیرد.
DIALIGN2 یک برنامه تحت وب است که برای یافتن تشابهات موضعی طراحی شده است. این روش از جریمه شکاف استفاده نمیکند بنابراین برای توالیهای بزرگ حساسیت ندارد. این روش هر توالی را به قطعات کوچکتری شکسته و تمام مقایسات دو به دو ممکن را بین این قطعات انجام میدهد.
۳-۱-۵-۶ همردیفی پیشرونده
همردیفیهای چندگانه برای آنالیز فیلوژنتیکی مفید هستند، همچنین اگر روابط فیلوژنتیک در یک مجموعه توالی شناخته شود، این اطلاعات میتواند برای ایجاد یک همردیفی چندگانه به کار رود. در واقع، این روابط دو جانبه به عنوان اساس یک روش ایجاد همردیفی چندگانهی اولیه که به طور همزمان درخت فیلوژنتیکی و همردیفی را ایجاد میکند، به کار رفته است. یک راه کوتاهتر، ایجاد یک درخت تقریبی از توالیها و به کار بردن آن برای ایجاد یک همردیفی چندگانه است؛ سرعت بالا و سادگی بسیار در این روش، آن را برای کارهای معمولی بسیار جذاب کرده است. یک درخت را میتوان به سرعت با ایجاد همهی همردیفیهای دو به دوی ممکن میان همهی توالیها و محاسبهی یک فاصله (یعنی نسبت ریشههایی که بین دو توالی متفاوت اند) در هر مورد رسم کرد. چنین فاصلههایی برای ایجاد درختی با یکی از روشهای فاصلهای رایج مانند روش NJ به کار میرود. برای نمونه، درختان NJ را میتوان به سرعت برای چند صد توالی به کار برد. بعد از آن، همردیفی به تدریج با ترتیب شاخهبندی در درخت شکل میگیرد. نخست، دو توالی بسیار مشابه با استفاده از برنامهریزی پویا، GPها و ماتریس وزنی همردیف میشوند. برای همردیفی بعدی، دو توالی به عنوان یک توالی (یا یک Subalignment) تلقی میشوند به طوری که هر گپ ایجاد شده میان دو توالی نمیتواند تغییر کند. دوباره، دو تا از شبیهترین توالیها یا گروههای همردیف شده با همدیگر همردیف میشوند. دو توالی همردیف نشده یا دو Subalignment میتوانند همردیف شوند یا یک توالی میتواند به یک Subalignment اضافه شود که بستگی به این دارد که کدام شبیهترند. این فرآیند تا زمانی که همه توالیها همردیف شوند، ادامه مییابد. تا زمانی که درخت اولیه ایجاد شود، همردیفی چندگانه میتواند با تنها N-1 همردیفی جداگانه برای N توالی انجام شود. این فرآیند به اندازهای سریع است که اجازهی همردیفی صدها توالی را میدهد.
۱-۳-۱-۵-۶ Clustal
رایجترین نرمافزار مورد استفاده برای همردیفی پیش رونده Clustalw و Clustax است. این برنامهها به صورت رایگان در دسترس میباشند. این برنامهها را میتوان با استفاده از سرور اینترنتی در مکانهای مختلفی به کار برد. Clustalw میتواند یک سری از توالیهای ورودی را بگیرد و به طور خودکار کل فرآیند همردیفی پیشرفته را انجام دهد. توالیها در جفتهایی برای ایجاد ماتریس فاصله مرتب میشوند که میتواند برای ایجاد درخت سادهی اولیه از توالیها به کار رود. این درخت راهنما در یک فایل ذخیره میشود و با استفاده از روش NJ درخت بدون ریشه را ایجاد میکند که برای راهنمایی در همردیفی چندگانه استفاده میشود. نهایتا همردیفی چندتایی با استفاده از روشهای پیشرفته که قبلا توضیح داده شد، طراحی میشود. Clustalw ویژگیهای خاصی دارد که به ایجاد همردیفهای دقیقتر کمک میکند. نخست، توالیها براساس میزان شباهت به سایر توالیها وزن داده میشوند (که به وسیلهی درخت راهنما مشخص میشود). این کار مفید است زیرا گروههای بزرگ توالیهای مشابه از غلبهی یک همردیفی جلوگیری میکند. دوم این که ماتریس وزنی مورد استفاده برای همردیفیهای پروتئینی بسته به میزان شباهت دو توالی بعدی یا مجموعهی توالیها متفاوت است. یک ماتریس وزنی برای توالیهای بسیار مشابه به کار میرود که امتیاز بالایی به ریشههای یکسان وامتیازات کمی به سایر موارد میدهد. برای توالیهای با شباهت کمتر، عکس این موضوع صحیح است؛ لازم است تا امتیازات بالایی به مطابقت اسیدآمینههای حفاظت شده داده شود و امتیاز کمتر به آنها که یکسان هستند. Clustalw مجموعهای از چهار ماتریس انتخاب شده از مجموعههای BLOSUM یا PAM را به کار میبرد. هنگام همردیفی؛ برنامه تلاش میکند تا GPهای متنوع در یک حالت اختصاصی توالی (یا اختصاصی موقعیت) بدهد که کمک میکند تا توالیهای با طولهای مختلف و شباهتهای مختلف همردیف شوند. GPهای اختصاصی موقعیت، برای متمرکز کردن گپها در حلقههای میان عناصر ساختار ثانویه به کار میروند که یا به صورت دستی یا به صورت خودکار انجام میشود. در هر مرحله، در موقعیتهای دارای ریشههای آبدوست یا در موقعیتهایی که در آنجا گپهای زیادی است، GPها کم میشوند. همچنین GPها نزدیک برخی ریشهها مانند گلیسین که بهطور تجربی نزدیک گپها شناخته شده، کاهش مییابد. GPها در مجاورت گپهای موجود و ریشههای خاصی افزایش مییابد. این مولفه و مولفههای دیگر قبل از هر همردیفی توسط کاربر قابل تنظیم هستند.
۱۳۸-فصل ششم
مجاورت گپهای موجود و ریشههای خاصی افزایش مییابد. این مولفه و مولفههای دیگر قبل از هر همردیفی توسط کاربر قابل تنظیم هستند.
Dbclustal یک الگوریتم جستوجوی بانک اطلاعاتی مبتنی بر clustal برای توالیهای پروتئینی است که از خصوصیت هر دو مقایسه بخشهایی از توالی و مقایسه کامل توالیها استفاده مینماید. PRALINE نیز یک برنامه مقایسه پیشرفته تحت وب است که در این برنامه ابتدا پروفایلی برای هر توالی با استفاده از ابزار PSIBLAST ایجاد میگردد. پروفایلهای پیش فرض شده سپس برای مقایسه چند تایی استفاده میگردند. در این روش مقایسهها به طور متوالی افزایش میابند.
معرفی Clustalw
یکی از برنامههای تحت وب معروف برای هم تراز کردن چندگانه توالیها است که از طریق EBI در دسترس میباشد. دو گونهی مختلف از این برنامه موجود است به نامهای ClustalW که واسط کاربر متنی دارد و ClustalX که دارای واسط کاربر گرافیکی است و دارای نسخههای قابل اجرا در سیستم عاملهای ویندوز، لینوکس و مکینتاش است. در الگوریتم کلاستال برای هم تراز کردن چند توالی با هم سه گام اصلی وجود دارد:
- انجام هم تراز کردن جفتی
- ساخت یک درخت فیلوژنتیک
- استفاده از درخت فیلوژنتیک برای هم تراز کردن چندگانه توالیها
با انتخاب گزینهی “Do Complete Alignment” همهی این مراحل به طور خودکار انجام میشوند. گزینههای دیگر شامل “Do Alignment from guide tree” و “Produce guide tree only” میباشد. کاربران میتوانند هم تراز کردن توالیها را با تنظیمات پیش فرض انجام دهند؛ هرچند معمولا با تغییر دادن تنظیمات با پارامترهای خاص خود نتیجهی بهتری بدست میآید. این پارامترها، جریمهی گشایش فاصله و جریمهی گسترش فاصله میباشند.
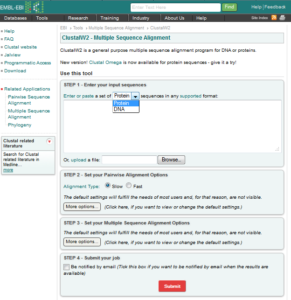
تصویر ۲۴-۶: نمایی از نرم افزار Clustalw.
نرم افزار دارای یک باکس میباشد که باید توالیهای نوکلوئیدی یا توالی اسید آمینه را با فرمت خاص در آن قرار داد که فرمت خاص آن طبق قانون زیر است

۱۳۹-هم ردیفی توالی ها
توالیها را براساس فرمت FASTA وارد باکس نرم افزار میکنیم و سپس با کلیک بر روی گزینه Submit نرمافزار شروع به alignment کردن sequenceها میکند. این نرم افزار توالیها را با یکدیگر مقایسه میکند و بیشترین شباهت را اعلام میکند
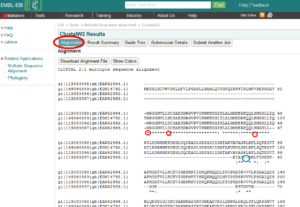

تصویر ۲۵-۶: یک نمونه نتیجه از نرم افزار Clustalw.
۲-۳-۱-۵-۶ معرفی T-Coffee
T-Coffee از Clustalw کندتر است اما همردیفی دقیقتری را ایجاد میکند (هنگام آزمون با BaliBase) که به دقت برنامههای DIALING یا PRRP است. این افزایش دقت در مشکلترین آزمونها و در تمام شاهدهای BaliBase مشاهده میشود. این روش براساس یافتن همردیفی چندگانهای است که بیشترین سازگاری را با یک مجموعه از همردیفیهای دوتایی میان توالیها داشته باشد. همردیفیهای دو به دو را میتوان از ترکیب منابع به دست آورد مانند برنامههای همردیفی مختلف یا انواعی از دادههایی که حاوی ساختارهای روی هم قرار گرفته و همردیفی توالی است. اینها برای یافتن جفتهای همردیف از ریشههای موجود در مجموعهی دادههای اولیه استفاده میشوند که بیشترین همانندی را در طول همردیفهای مختلف داشته باشند. پس این اطلاعات، برای جمعآوری دادهها روی ریشههای بسیار مشابه به همردیفی توالیها استفاده میشود. مرحلهی آخر، اضافه کردن همردیف چندگانه با استفاده از همردیفی پیشرفته معمولی است که سریع و ساده است و به پارامتر دیگری مانند GPها یا ماتریس وزنی نیاز ندارد. معایبT-Coffee در برابرClustalw زمان زیاد مورد نیاز رایانه برای همردیفی است. ظرفیت آن برای وارد کردن تنها ۵۰ توالی است که در طول زمان در نرمافزارهای جدیدتر افزایش مییابد. ابزاری تحت عنوان ۳D-Coffee وجود دارد که مدلی اختصاصی از T-Coffee
۱۴۰-فصل ششم
T-Coffee از Clustalw کندتر است اما همردیفی دقیقتری را ایجاد میکند (هنگام آزمون با BaliBase) که به دقت برنامههای DIALING یا PRRP است. این افزایش دقت در مشکلترین آزمونها و در تمام شاهدهای BaliBase مشاهده میشود. این روش براساس یافتن همردیفی چندگانهای است که بیشترین سازگاری را با یک مجموعه از همردیفیهای دوتایی میان توالیها داشته باشد. همردیفیهای دو به دو را میتوان از ترکیب منابع به دست آورد مانند برنامههای همردیفی مختلف یا انواعی از دادههایی که حاوی ساختارهای روی هم قرار گرفته و همردیفی توالی است. اینها برای یافتن جفتهای همردیف از ریشههای موجود در مجموعهی دادههای اولیه استفاده میشوند که بیشترین همانندی را در طول همردیفهای مختلف داشته باشند. پس این اطلاعات، برای جمعآوری دادهها روی ریشههای بسیار مشابه به همردیفی توالیها استفاده میشود. مرحلهی آخر، اضافه کردن همردیف چندگانه با استفاده از همردیفی پیشرفته معمولی است که سریع و ساده است و به پارامتر دیگری مانند GPها یا ماتریس وزنی نیاز ندارد. معایبT-Coffee در برابرClustalw زمان زیاد مورد نیاز رایانه برای همردیفی است. ظرفیت آن برای وارد کردن تنها ۵۰ توالی است که در طول زمان در نرمافزارهای جدیدتر افزایش مییابد. ابزاری تحت عنوان ۳D-Coffee وجود دارد که مدلی اختصاصی از T-Coffee میباشد که براساس اطلاعات ساختاری عمل میکند. همچنین ابزار دیگر تحت عنوان Expresso نیز وجود دارد که از روش همترازی چندگانه مبتنی بر ساختار استفاده میکند و کاربر فقط توالی مورد نظر خود را وارد میکند و نرمافزار توسط BLAST هومولوگهای مناسب برای توالی مورد نظر کاربر را از بانک PDB پیدا میکند. همچون SAP و Fugc که از روش همترازی چندگانه براساس ساختار استفاده میکنند در اینجا نیز این هومولوگهای بهدست آمده از PDB براساس ساختار تحت همردیفی چندگانه قرار میگیرند.
۲-۵-۶ الگوی مخفی مارکوف
یک روش جذاب برای همردیفی “الگوی مخفی مارکوف” (HMM) است که براساس احتمال جایگزینی ریشهها و وارد شدن یا حذف گپها است. نشان داده شده که HMM در شرایط متنوع زیستشناسی مولکولی محاسباتی مفید است؛ مانند جستوجوی اینترون و اگزونها یا پیشبینی پروموترها در توالیهای DNA. همچنین، HMM برای خلاصه کردن اطلاعات متنوع در همردیفی موجود از توالیها و پیشبینی این که توالی جدید متعلق به چه خانوادهای است، مفید میباشد. برخی بستههای نرمافزاری تولید HMM و یافتن همردیفی توالیهای نامرتب را با هم انجام میدهند. این روشها دقیق نیستند؛ با وجود این، پیشرفتهایی شکل گرفته و اکنون روش SAM مربوط به Hughey و Krogh (1996) از نظر دقت قابل مقایسه با Clustalw است هر چند به آن اندازه آسان و سریع نیست.
۳-۵-۶ توالیهای نوکلئوتیدی در برابر توالیهای آمینواسیدی
شاید توالیهای نوکلئوتیدی رمز کننده باشند یا نباشند. در موارد دیگر، ممکن است آنها رمز کنندهی انواع RNAی کاتالتیک یا ساختاری باشند اما بیشتر آنها رمزکنندهی پروتئین هستند. در مورد ژنهای رمزکنندهی پروتئین، همردیفی را میتوان براساس توالی نوکلئوتیدی یا اسیدآمینهای انجام داد. شاید این انتخاب تحت تأثیر نوع آنالیز بعد از همردیفی باشد؛ برای نمونه، شاید دگرگونیهای خاموش در توالیهای بسیار مشابه بررسی شود. در این مورد، آنالیز همردیفی آمینواسیدی مفید نیست زیرا اختلاف کمی میان توالی وجود خواهد داشت. بالعکس، اگر توالیها دور از هم باشند، آنالیز را میتوان هم با اختلاف آمینواسیدی و هم نوکلئوتیدی انجام داد. صرف نظر از مطلوب بودن آنالیز نهایی، همردیفی توالی آمینواسیدی آسانتر و واضحتر از همردیفیهای نوکلئوتیدی است که در مورد جستوجوی پایگاه اطلاعات توالیها چنین است؛ علاوه بر این دلایلی که بحث شد، بیشتر برنامههای همردیفی یک کدون را به عنوان یک واحد توالی نمیشناسند که آنها را هنگام همردیفی جدا کنند. این موضوع برای همردیفی دو توالی معین و برنامههای جستوجوی پایگاه دادهها درست نیست اما در مورد بیشتر برنامههای همردیفی چندگانه درست است. یک روش متداول، انجام همردیفی در سطح اسیدآمینه و استفاده از آن برای ایجاد یک همردیفی توالی نوکلئوتیدی متناظر است که سپس میتواند به طور معمول آنالیز شود. برنامههای کامپیوتری مختلفی برای این کار در دسترس هستند مانند PROTAL2DNA یا DAMBE.
اگر توالیها، رمزکنندهی پروتئین نباشد پس همردیفی نوکلئوتیدی تنها راه است. اگر توالی، رمزکنندهی RNAی ساختاری باشد (ماننده RNAی زیرواحد کوچک ریبوزوم یا rRNA SSU)، همردیفی با عملکرد ساختار اولیه و ثانویه، حداقل در بخشی از طول آنها، محدود میشود. معمولا بخشهایی با همانندی واضح نوکلئوتیدی وجود دارد که میان بخشهایی که سریعتر دگرگون میشوند، قرار گرفتهاند؛ کارایی نرمافزار بستگی به چنین شرایطی دارد. بیشتر برنامههای رایج برای rRNA، همردیفی بخشهای اصلی بزرگی که میان فواصل زیاد فیلوژنتیکی حفاظت شدهاند را مدیریت میکنند. با این حال، این قطعات اصلی همردیف شده با قطعات بسیار متغیر، پراکنده شدهاند؛ بیشتر برنامهها با این قطعات مشکل دارند. شاید در نظر گرفتن ساختار ثانویه، با استفاده از یک ویرایشگر اختصاصی RNA بتواند کمک کند اما هنوز هم پیدا کردن یک همردیفی واضح مشکل است. حذف این نواحی در آنالیز بعدی باید به طور جدی در نظر گرفته شود. اگر همردیفی اختیاری باشد، آنالیز بعدی ضروری نیست. خوشبختانه، قطعات حفاظت شدهی تقریبا واضحی در همردیفی وجود دارد تا برای انجام آنالیز فیلوژنتیکی استفاده شود.
پس در توالیهای نوکلئوتیدی که رمزکننده نیستند (مانند SINES یا اینترونها)، هنگامی که توالیها بیش از سطح مشخصی از هم دور باشند، ممکن است همردیفی مشکل باشد. توالیهایی که محدودیت زیادی ندارند، میتوانند حذف و اضافه و جایگزینیها را در همهی موقعیتها جمع کنند؛ این قطعات غیر قابل همردیفی هستند. اگر توالیها تکرارهای کوچک داشته باشند، هیچ راه حل الگوریتمی وجود ندارد و به خصوص این حالت بسیار مشکل است. حتی اگر تا حدی همردیفی مطلوبی با استفاده از یک امتیاز همردیفی یا پارسمیونی به دست آید، دلیلی برای این که این همردیفی از نظر زیستی پاسخگو باشد، وجود ندارد. چنین امتیازاتی براساس فرضیههای اختیاری دربارهی جزئیات فرآیند تکاملی در توالیها است. حتی اگر جزئیات فرضیهها توجیهپذیر باشد، همردیفی به قدری مبهم است که شبیه توالیهایی است که در آنها همردیفی غیر قابل دستیبای است. اگر یک همردیفی با یک همردیفی دیگر تایید نشود، باید با احتیاط با آن رفتار کرد.
۱۴۱-هم ردیفی توالی ها
۶-۶ مروری بر ابزارهای تجزیه و تحلیل توالیهای نوکلئوتیدی:
BLAST: از این برنامه برای مقایسهی توالی DNA و پروتئین با توالیهای دیگر در همهی پایگاههای اطلاعاتی استفاده میشود. اکنون این برنامه به صورت مختلفی شامل BLAST، PHI-BLAST و PSI-BLAST ارایه شده است. BLAST به عنوان یکی از ابزارهای همردیفی توالیهای DNA و پروتئین در این فصل به طور کامل توضیح داده شده است.
PCR الکترونیکی: این ابزار اجازهی جستوجوی STSها (به عنوان نشانه یا راهنما[۱] در انواع مختلفی از نقشههای ژنومی) در توالی DNA مورد نظر را میدهد. منبع UniSTS حاوی تمام اطلاعات در زمینهی نشانگر STS از قبیل توالی آغازگر، طول محصول، اطلاعات نقشه و اسامی دیگر آن است.
Entrez Gene: دامنه وسیعی از اطلاعات دربارهی ژنها و موجودات را در بر دارد. این اطلاعات شامل نتایج تجزیه و تحلیلهایی است که روی دادههای توالی صورت گرفته است. مقدار و نوع اطلاعات ارائه شده وابسته به این است که چه اطلاعاتی راجع به یک ژن و یا موجود مشخص در دسترس است و میتواند شامل ۱) خلاصه گرافیکی محتوی ژنومی، ساختار اگزون/ اینترون، ۲) تصویر گرافیکی توالی mRNA، ۳) انتولوژی ژنی و اطلاعات مربوط به فنوتیپ، ۴) دادههای توالی پروتئینی و دمینهای حفظ شده، ۵) پایگاههای اطلاعات مربوط به جهش باشد.
Model Maker: امکان ایجاد توالی mRNA از روی توالی ژنوم را فراهم میکند. در حقیقت با کمک این ابزار را میتوان برای ساخت یک مدل ژنی دلخواه و یا ویرایش مدل از راه انتخاب یا حذف اگزونهای مورد نظر بهره جست.
ORF Finder: این برنامه ORFهای ممکنه در یک توالی DNA را به وسیلهی قرار دادن کدونهای شروع و پایان مشخص مینماید. همچنین توالی آمینواسیدی استنباط شده را میتوان با استفاده از ابزار BLAST در NCBI بررسی کرد.
SAGEmap: ابزاری برای انجام آزمونهای آماری برای تجزیه و تحلیلهای مختلف دادههای SAGE[۲] میباشد. با وارد کردن یک توالی تقاضا در منبع SAGEmap، میتوان فهمید که آیا قطعات SAGE در توالی وجود دارد یا خیر.
Spidey: همردیفی یک و یا بیش از یک توالی mRNA را با یک توالی ژنومی فراهم میکند. این برنامه همچنین ساختار اگزون/ اینترون را تعیین خواهد کرد.
Splign: برای محاسبهی همردیفیهای cDNA با DNA ژنومی براساس یک نوع ویژه از الگورتیم نیدلمن و وانچ به همراه ابزار BLAST عمل میکند.
Vec Screen: ابزاری برای شناسایی قطعات یک توالی اسید نوکلئیکی (که ممکن است حاصل یک حامل، لینکر یا سازگارساز باشد)، قبل از تجزیه توالی است.
Viral Genotyping Tool: یک برنامه مبتنی بر شبکه است، که ژنوتیپ توالیهای نوکلئوتیدی ویروسهای نوترکیب و غیرنوترکیب را مشخص میکند. این برنامه با کمک BLAST مقایسهی یک توالی ورودی را با مجموعهای از توالی منبع (با ژنوتیپهای شناخته شده) انجام میدهد. ژنوتیپهای منبع از قبل برای پاتوژن ویروس شامل HIV-1، هپاتیت C و هپاتیت B و همچنین پولوویروسها[۳] مشخص و در دسترس هستند.
[۱] Landmark
[۲] Serial Analysis of Gene Expression
[۳] Poliovirus