- 842
- ۱۴۰۲/۰۲/۰۷ - ۰۴:۵۰
- 672 بازدید
شرح فصل و نکات ویژه: در این فصل به پروتئومیکس و تجزیه و تحلیل دادههای آن میپردازیم. ایمونوانفورماتیک مبحث جدید و جذابی میباشد که در این فصل به آن خواهیم پرداخت. از جدیدترین وقایع حوزه علوم زیستی انجام پروژه پروتئوم انسان میباشد که مراکز مختلفی از نقاط مختلف دنیا در آن همکاری میکنند، از جمله پژوهشگاه رویان از ایران که پروژه پروتئوم کروموزوم Y را بر عهده دارد. حیطههای کارکردی ایمونوانفورماتیک در ایمونولوژی در این فصل شرح[…]
شرح فصل و نکات ویژه:
- در این فصل به پروتئومیکس و تجزیه و تحلیل دادههای آن میپردازیم.
- ایمونوانفورماتیک مبحث جدید و جذابی میباشد که در این فصل به آن خواهیم پرداخت.
- از جدیدترین وقایع حوزه علوم زیستی انجام پروژه پروتئوم انسان میباشد که مراکز مختلفی از نقاط مختلف دنیا در آن همکاری میکنند، از جمله پژوهشگاه رویان از ایران که پروژه پروتئوم کروموزوم Y را بر عهده دارد.
- حیطههای کارکردی ایمونوانفورماتیک در ایمونولوژی در این فصل شرح داده میشود.
- بانکهای اطلاعاتی مربوط به پیشبینی اپیتوپهای سلولهای B و Tدر این فصل معرفی میشوند.
پیشنهاد مطالعاتی:
- کتاب “آشنایی با پروتئومیکس” نوشته “ناوین چاندرا” ترجمه “سیدحسن حسنی کومله” از انتشارات دانشگاه گیلان کتابی مناسب برای درک بیشتر مباحث پروتئومیکس میباشد.
۱۷۰-فصل هشتم
واژه پروتئوم اولین بار توسط ویلکلینز در سال ۱۹۹۴ مطرح شد. اصطلاح proteom متشکل از دو بخش کلمههای PROTein و genOME تشکیل شده است. واژه پروتئوم به کل پروتئینهایی اطلاق میشود که ژنوم موجود زنده تولید میکند و پروتئومیکس علمی است که به شناسایی ویژگیهای پروتئوم موجود زنده میپردازد. امروزه مطالعه پروتئوم و تغییرات آن در محیط و در فرآیند توسعه را پروتئومیکس مینامند. این فناوری مکملی بر سایر راهکارهای ژنومیکس عملکردی مانند فناوری ریزآرایه است و تلفیق اطلاعات آنها از طریق بیوانفورماتیک میتواند اطلاعات بسیار غنی از بیان و عملکرد ژن را در اختیار قرار دهد. یکی از جنبههای جالب حیاط این است که با وجود این که یک موجود دارای یک ژنوم است، میتواند ترانسکریپتوم و پروتئومهای مختلفی داشته باشد که متعلق به بافتها، مراحل تکوینی و شرایط مختلف باشند. پروتئومیکس در واقع یک روش تفکیکی است، از این روش معمولا برای مقایسه پروفایلهای پروتئینی استفاده میشود که در شرایط مختلف یا در بافتهای متفاوت بیان شدهاند.
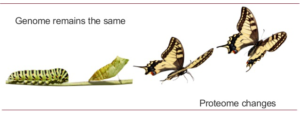
تصویر ۱-۸: اختلاف پروتئوم در مراحل مختلف زندگی پروانه.
Ofarrel و Klose به طور مستقل به توصیف کل پروتئینهای موجود زنده پرداختند و با هم باعث رشد و توسعه الکتروفورز دو بعدی شدند. با الکتروفورز دو بعدی میتوان مخلوط پیچیده بیش از ۱۱۰۰ پروتئین اشرشیاکلی را به صورت باندهای مجزا روی ژل جدا کرد. پژوهشگران ساختن بانک اطلاعات پروتئین را با استفاده از الکتروفورز دو بعدی (۲DE) شروع کردند. با پیشرفت سریع ژنومیکس در دهه ۹۰ و پایان توالییابی ژنوم موجودات یوکاریوت و پروکاریوت مهم، عصر جدیدی در بیولوژی مولکولی آغاز شده است که در آن بیان و عمل ژن در محل توجهات قرار گرفت و همچنین علم پروتئومیکس با استفاده از طیف سنجی جرمی همراه با ژنومیکس برای جداسازی و شناسایی پروتئینها در مقیاس بزرگتر دستخوش انقلاب شد. الکتروفورز دو بعدی با قدرت تفکیک زیاد، ابزار پایه پروتئومیکس است که تجزیه همزمان هزاران پروتئین را میسر میسازد. این روش از سال ۱۹۷۵ مورد استفاده قرار گرفته است اگر چه در طول سالهای گذشته تغییرات اساسی در آن ایجاد گردید. مراحل مختلف تجزیه پروتئوم بر پایه الکتروفورز دو بعدی، آشکارسازی پروتئینها و تجزیه و تحلیل آنهاست. پروتئومیکس به سه شاخه اصلی به نامهای پروتئومیکس الگوی تظاهر (شناسایی کل پروتئینهای یک سلول یا بافت تحت شرایط زیستی خاص)، پروتئومیکس ساختاری (در این بخش هدف تعیین ساختار کمپلکسهای پروتئینی است) و پروتئومیکس عملکردی (در این بخش هدف شناخت وظیفه و عمل پروتئینها در سطح سلولی است)تقسیم میشود.
امروزه شاهد استفاده از مطالعات پروتئومیکس در شاخههای مختلف علم زیست شناسی هستیم و جدیدترین این مطالعات مربوط به بررسی سیستمهای ایمنی و مقایسه آنها در سلولهای سالم و بیمار میباشد از جمله مطالعات بر روی MHC و اختصاصیت آنتیبادی و آنتیژن، بررسی نقش محرکهای ویروسی و سلولهای التهابی در پاتوژنز، فلوسایتومتری فسفر و طیف سنجی جرمی برای تجزیه و تحلیل ایزوتوپ مبتنی بر مسیرهای سیگنالینگ در سطح تک سلول، ارزیابی سهم سایتوکاینها، کموکاینها، فاکتورهای رشد در مسیرهای سیگنالینگ. با توجه به اهمیت این موضوع شاهد شکل گیری گروههای تحقیقاتی تخصصی در رابطه با مطالعات پروتئومیکسی ایمونولوژی هستیم مثل گروه NHLBI Proteomics Center for Systems Immunology در دانشگاه استفورد که به تحقیقات پیشرویی در این زمینه دست زده است. تجزیه و تحلیلهای پروتئومیکس امروزه به عنوان یکی از روشهای مهم در مطالعات بیان ژنها و ژنومیکس عملکردی محسوب میشوند. استفاده از این روشها به چند دلیل ضرورت دارند:
- امروزه مشخص شده است که بین سطح m-RNAو پروتئینها و حتی گاهی توالی آنها رابطه دقیقی بر قرار نیست.
- توالیهای DNAو RNAاطلاعات بسیار کمی را در مورد جایگاه پروتئینها،تغییرات پس از تر جمه و نیمه عمر پروتئینها به ما میدهند.
- با استفاده از روشهای پروتئومیکس تعداد زیادی ازپروتئینها را میتوان هم زمان در یک ترکیب پیچیده مانند محتویات یک سلول لیز شده مورد بررسی قرار داد.
۱۷۱-پروتئومیکس و ایمیونومیکس
نکاتی پیرامون بحث پروتئومیکس
– بین فراوانی mRNA و فراوانی پروتئین در سلول ارتباط کَمی وجود دارد.
– پروتئینها موقعیت ممتازی نسبت به سایر مولکولهای زیستی دارند چون نه تنها با ژنها ارتباط دارند بلکه تمام خصوصیت کاتالیتیک، ساختمانی و دیگر لوازم ضروری برای انجام واکنش خود را برخوردارند. همچنین با توجه به این که واکنش با عوامل محیطی توسط پروتئینها انجام میشود نقش مهم پروتئینها را میرساند.
– محصولات پروتئین یک ژن در بسیاری از حالات ثابت نبوده، بلکه اشکال کواوالانس مختلفی را نشان میدهند که بستگی به نوع سلولی دارد.
– در بسیاری از تغییرات محیطی میزان بیان پروتئین تغییری نمیکند بلکه پاسخهای لازم از راه فرایندهای فراژنومی گستردهای نظیر تغییرات پروتئولیتیک انجام میشود که شکل کووالانسی یک پروتئین را تغییر میدهند.
– تنوع پروتئین اغلب به دلیل سنتز بیش از یک پروتئین از یک mRNA و همچنین تغییرات بعد از ترجمه بیشتر از ترانسکریپتوم است.
– فعالیت پروتئین به تغییرات پس از ترجمه بستگی دارد. و ممکن است فراوانی پروتئین بیانگر سطح فعالیت آن در سلول نباشد.
– عملکرد یک پروتئین به محل قرارگیری صحیح آن بستگی دارد.
– پروتئوم براساس شرایط و نوع سلول یا محیط و … متفاوت است.
۱-۸ مراحل یک مطالعه پروتئومیکسی
مراحل کار را میتوان به دو دسته تقسیم کرد که مرحله اول آماده سازی نمونه و تلخیص و انجام الکتروفورز میباشد و مرحله دوم تجزیه و تحلیل کامپیوتری و استفاده از بانکها میباشد.
آماده سازی و نمونه برداری
یکی از کاربردهای مهم پروتئومیکس مطالعه کمی تغییرات پروتئینهاست که مستلزم تکرار پذیری کل مراحل میباشد. اگر کار مطالعاتیمان بر روی گیاه باشد،گیاهان باید در تکرارهای کافی و شرایط یکسان رشد داده شده و نمونههای قابل انطباق برداشت شوند. تکرار پذیری در شرایط کنترل شده راحت تر انجام میشود، اما باید تا حد ممکن شرایط مشابه با حالت طبیعی را فراهم کرد. برای مثال، در آزمایشهای مربوط به تنش خشکی در مزرعه، تنش به طور تدریجی اعمال میشود. به منظور مشابه سازی، میتوان در گلخانه، گلدانها را به اندازه کافی بزرگ گرفت تا شرایط مشابه مزرعه ایجاد شود. پس از جمع آوری اطلاعات در شرایط کنترل شده، میتوان آزمایش را در مزرعه تکرار کرد تا این دادهها در شرایط واقعی به آزمون گذاشته شوند.
۱-۱-۸ استخراج پروتئین
روشهای مختلفی برای استخراج پروتئین معرفی شده است که در میان آنها روش دامروال و همکاران بیشتر مورد استفاده محققان قرار میگیرد که اغلب موارد نیز با تغییراتی همراه است. هر روشی که برای استخراج پروتئینها استفاده میشود، باید دارای ویژگیهای زیر باشد:
– مواد زاید از جمله DNA، RNA، ترکیبات فنلی، رنگدانهها، و مواد فیبری را حذف کند؛
– از فعالیت پروتئازها جلوگیری کند؛
– تمام پروتئینها را به صورت محلول در آورد؛
۲-۱-۸ الکتروفورز دو بعدی:
در الکتروفورز دو بعدی، پروتئینها در دو بعد جدا میشوند، در بعد اول یا IEF پروتئین بر اساس نقطۀ ایزوالکتریک (pI) و در بعد دوم بر اساس وزن مولکولی جدا میشوند. در سال ۱۹۸۸ گروهی از پژوهشگران با ایجاد اصلاحات مهمی در بعد اول الکتروفورز دو بعدی، پروتکل پایه ای را برای استفاده از شیبهای pH ثابت شده، یا IPGs ارائه دادند. این روش تا حد زیادی قدرت تفکیک و تکرار پذیری الکتروفورز دو بعدی را افزایش داده و امکان بارگیری مقادیر بیشتری پروتئین را بر روی هر ژل فراهم ساخته است. همچنین در بعد دوم نیز بهبود زیادی حاصل شده است. دستگاههای جدید، امکان اجرای همزمان چندین ژل را فراهم میسازد.
۱۷۲-فصل هشتم
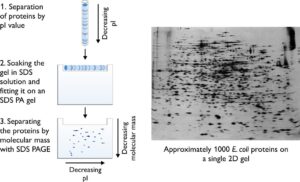
تصویر ۲-۸: مراحل انجام الکتروفورز دو بعدی (سمت چپ). تصویر واقعی از ژل دو بعدی رنگآمیزی شده (سمت راست).
اگرچه الکتروفورز دو بعدی خود ابزار تفکیک کننده قدرتمندی است، ولی در بسیاری از موارد دانستن نقطه ایزوالکتریک و وزن مولکولی برای شناسایی دقیق پروتئینها کفایت نمیکند. زیرا در بسیاری از موارد دو یا چند پروتئین متفاوت ممکن است نقطه ایزوالکتریک و وزن مولکولی مشابه داشته باشند. با این حال، از این روش برای جداسازی پروتئینهای منفرد و تعیین خصوصیات آنها به روشهای دیگر نیز استفاده میشود. در روش ادمن (Edman) از انتهای آمینی پروتئین مورد نظر توالییابی میشود. سپس با استفاده از جستوجوی توالی این ناحیه در پایگاه دادهها پروتئین مورد نظر شناسایی شود. در روشی دیگر میتوان پروتئین مورد نظر را از روی ژل جدا کرد و با استفاده از هضم آنزیم قطعات پپتیدی را به روش ادمن توالییابی کرد. این روش از روش قبلی اطلاعات بیشتری را به ما میدهد. ولی باید توجه کرد که برای انجام این روش مقدار زیادی پروتئین نیاز است بعلاوه در بیشتر از ۵۰ درصد پروتئینها انتهای آمینی بلوک شده است و نمی توان آنها را توالییابی کرد.
الکتروفورز دو بعدی با روشهای مختلف انجام میشود که یکی از این روشها DIGE میباشد. Differential in Gel Electrophoesis
که بهصورت مخفف DIGE نامیده میشود یک تکنیک برای نظارت بر تفاوتهای پروفایلهای پروتئومیک بین سلولها در حالتهای عملکردی مختلف است. این تکنیک در سه مرحله انجام میشود. ابتدا نمونهها با رنگهای فلورسنت منحصر به فرد برچسبگذاری میشوند (یعنی هر نمونه با یک رنگ مختلف رنگآمیزی میشود) و سپس نمونهها در ژل الکتروفورز دو بعدی میشوند. در نهایت، پس از اتمام الکتروفورز، تصاویر مختلف فلورسنت با یکدیگر مقایسه میشوند. این تکنیک اجازه میدهد تا پروتئینهایی که بهصورت متفاوتی بیان شدهاند را مطالعه کنیم و امکان مقایسه تا سه نمونه در یک ژل در این تکنیک وجود دارد.
۳-۱-۸ شناسایی پروتئینها
مقایسه کمی فراوانی پروتئینها بین دو ژل ۲D-PAGE تنها زمانی میسر است که روش مورد استفاده قابل تکرار و تغییرات جزئی پروتئین به پروتئین را نشان دهد. رنگ آمیزی Coomassie Blue یکی از قدیمیترین روشهای رنگآمیزی پروتئینها است که امروزه نیز به طور وسیعی مورد استفاده قرار میگیرد. ولی این روش نیاز به استخراج مقدار زیادی پروتئین دارد زیرا حساسیت آن کم است و در روش الکتروفورز دو بعدی در مواردی امکان پذیر نمیباشد. رنگآمیزی با نیترات نقره روش بهتر و عمومیتری است چرا که حساسیت بیشتری دارد. با این حال، در بعضی از موارد این رنگ با ویژگیهای پروتئینها تداخل میدهد. روش دیگر، نشاندار کردن پروتئینها با رادیو اکتیو قبل از انجام بعد اول الکتروفورز در شرایط آزمایشگاهی است. در شرایط طبیعی این رنگ آمیزی در مواردی سخت جواب میدهد ولی اگر بتوان با این روش پروتئینهای سلول را رنگ آمیزی کرد روشی بسیار حساس برای تشخیص پروتئینها ست.
۱۷۳-پروتئومیکس و ایمیونومیکس
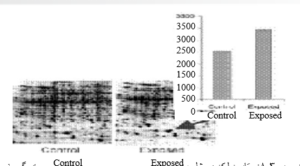
تصویر ۳-۸: مقایسه لکه در ژل دو بعدی کیس و کنترل توسط نرم افزارهای تیرگیسنج و نمایش نتیجه به صورت نمودار.
در دو دهه اخیر، سختافزارها و نرم افزارهای تیرگی سنجی برای اسکن ژلهای الکتروفورز دو بعدی با دقت مناسب طراحی شدهاند که با استفاده از آنها میتوان بسیاری از تجزیه و تحلیلهای مربوط به تصاویرهای گرفته شده را انجام داد. این برنامهها توانایی تشخیص نقاط پروتئینی و تعیین میزان بیان و جرم پروتئین مورد نظر را دارا هستند. ضمن این که توانایی مقایسه ژلهای مختلف با هم و تشکیل بانکهای اطلاعاتی در این زمینه را دارند. پایگاه اطلاعاتی SWISS-2DPAGE حاوی تصاویر ژلهای الکتروفورز دو بعدی است که با اطلاعات پایگاههای توالی پروتئینی مانند Swiss-Prot و PIR مرتبط شدهاند. به طوری که با کلیک روی لکههای هر تصویر میتوان به استنادات آن لکه پروتئینی دست یافت. لازم به تاکید است هر تصویر ژل منعکس کننده پروفایل پروتئینهای بیان شده در شرایط خاص و در بافتی خاص است. تغییرات پروتئینی بر روی ژلهای الکتروفورز دو بعدی میتواند کمی یا کیفی باشد. تغییرات کیفی میتواند به صورت حضور یا عدم حضور (P/A) و یا تغییرات مکانی (PS) باشد.
شناسایی پروتئینها با اسپکترومتر جرمی
مهم ترین تحول در پروتئومیکس، شناسایی پروتئینهای جدا شده از روی ژل با استفاده از اسپکترومتر جرمی است که قدرت شناسایی پروتئینها در حد پیکومول را دارد. این روش جایگزین تعیین ردیف ادمن (Edman) شده است که حساسیت کمتری دارد، کمتر اتوماتیک بوده و به مسدود بودن انتهای آمین پروتئین حساس است. معمولاً تجزیه اسپکترومتر جرمی با نقشه نگاری پپتید آغاز میشود که روشی سریع و نسبتاً ارزان است. این روش در ابتدا توسط هنزل و همکاران معرفی شد که در آن پروتئین با آنزیم هضم شده و جرمها با جرمهای حاصل از هضم فرضی پروتئینهای موجود در بانک اطلاعات توالی پروتئین مقایسه میشوند. امروزه از این روش بیشتر به عنوان انگشت نگاری جرم پپتید نام برده میشود. در کل، این روش تا حد زیادی اتوماتیک است، اما نیازمند حضور ردیف کامل پروتئین (یا ناحیۀ کد کنندۀ ژن) در بانک اطلاعاتی و مطابقت کامل با این ردیفهاست. بنابراین با افزایش تعداد ژنهای موجود، موفقیت این روش نیز افزایش مییابد. در حالتی که نتوان با انگشت نگاری، جرم پپتید پروتئین را با اطمینان شناسایی کرد، باید روش پیچیدهتری مانند MS/MS استفاده کرد که قطعههای پپتید و ردیف جزیی پپتیدها را به دست میدهد. در مقایسه با طیفهای جرمی قطعههای پپتید حاصل از MS/MS حاوی اطلاعات غنی از بخش کوچکی از پروتئین است و میتوان از این طیفها برای جستوجوی بانک اطلاعاتی پروتئین و اسید نوکلئیک پرداخت، بدین ترتیب میتوان با اطمینان و موفقیت بیشتری پروتئین را شناسایی و همچنین در صورت لزوم، به طراحی آغازگر PCR و جداسازی cDNA مربوطه اقدام کرد.
روش طیفسنجی جرمی
روش طیفسنجی جرمی یا Mass Specterometry یکی دیگر از روشهای قوی و حساس در تعیین خصوصیات پروتئینهایی است که توسط روش الکتروفورز دو بعدی جدا میشوند. در این روش پروتئینها بر اساس نقشه پپتیدی شناسایی میشوند که توسط اسپکترومتری MALDI (matrix assisted laser adsorbtion/ionization) انجام میشود. به این صورت که پروتئین مورد نظر از ژل جدا شده و تحت هضم آنزیمی یا شیمیایی قرار میگیرد تا به پپتیدهایی تبدیل شود. سپس جرم پپتیدها توسط اسپکترومتر جرمی تعیین میگردد. در این روش پپتیدهای که ایجاد شدهاند باردار میشوند، سپس در مسیر اسپکترومتر جرمی برای ماکرومولکولها قرار میگیرند و بر اساس جرم از هم جدا میشوند طیف آن به صورت پیکهایی ثبت میشود.
۱۷۴-فصل هشتم
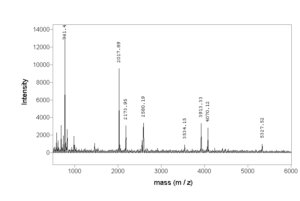
تصویر ۴-۸: یک نمونه رکورد Mass Specterometry.
با استفاده ار نرمافزارها الگوی برشی توالیهای پروتئینهای موجود در پایگاههای دادههای اولیه پروتئینی تحت تاثیر آنزیمهای پروتئاز یا مواد شیمیایی خاص (مانند سیانید بروماید) پیشبینی میشود. نتیجه این کار تولید پایگاه اطلاعاتی جدیدی است که در آن جداولی از جرم مولکولی پلی پپتیدهای حاصل از هضم ذخیره شده است. پایگاههای اطلاعاتی PeptIdent و MassCot از جمله چنین پایگاههای اطلاعاتی است. پس از تعیین جرم پپتیدها در آزمایشگاه و در اختیار داشتن پایگاههای مزبور، از ابزارهای جستوجو برای مقایسه الگوی جرمی به دست آمده برای پپتیدهای یک پروتئین با الگوهایی که به صورت تئوری و فرضی در پایگاه دادهها استفاده میشود. هر قدر اندازهگیری جرم پپتیدها با دقت بیشتری صورت گیرد، تعداد پپتیدهایی که در پایگاه داده با پپتید مورد نظر جفت میشوند، بیشتر خواهد بود و ارتباط دقیق تری با اطلاعات بانک مورد نظر بر قرار میشود. در نهایت میتوانیم با اطمینان بیشتری پروتئین مورد نظر خود را شناسایی کنیم.
روشهای شناسایی پروتئین به وسیله طیفسنج جرمی مبتنی بر دو راهبرد اصلی Bottom-up و Top-down است. در راهبرد Bottom up لکه پروتئین از ژل خارج میشود و مورد هضم آنزیمی قرار میگیرد، سپس مخلوط پپتیدی حاصل از هضم آنزیمی به وسیله طیفسنج جرمی MALDI-TOF یا ESI-MS بررسی میشود و جرمهای به دست آمده در بانک جستوجو میشوند. هر چه تعداد پپتیدهای حاصل از هضم آنزیمی یک پروتئین بیشتر باشد، امکان شناسایی دقیق پروتئین به روش انگشتنگاری جرم پپتیدی (PMF) بیشتر است. یکی از مشکلات PMF ابهام در شناسایی پروتئینهایی با طول مشابه و محتوی اسیدآمینهای یکسان اما با چینش متفاوت میباشد. مثلا پپتیدهای LHEPV، LEPVH و HEPVL همگی وزن جرمی یکسانی دارند در حال حاضر الگوریتمهای متفاوتی برای انجام جستوجوی جرم پپتیدی به کار میرود که یکی از آنها الگوریتم SEQUEST است.
دلیل استفاده از راهبرد دوم این مسئله میباشد که پروتئینها دچار تغییرات پس از ترجمه میشوند و این مساله باعث تفاوت در جرم پیشبینی شده و جرم اندازهگیری شده میشود و به این دلیل در روش Top-down اطلاعاتی از ساختار اولیه پروتئین بدون نیاز به هضم آنزیمی به محقق ارایه میدهد. در این روش پروتئین سالم را یونیزه میکنند، سپس پروتئین حاصل را برای طیفسنجی جرمی قطعه قطعه میکنند و طیف جرمی قطعات حاصل را به دست میآورند و وزن جرمی را در بانک جستوجو میکنند.
۲-۸ پایگاههای آنلاین در زمینه پروتئومیکس
پایگاههای آنلاین زیادی در زمینه آنالیز دادههای پروتئومیکس وجود دارد برای مثال ProFound ابزاری به منظور جستوجوی نتایج طیفسنجی جرمی میباشد. در ابتدا نرمافزار از شما جرمهای پپتیدی حاصل اسپکترومترهای جرمی را دریافت میکند و سپس جستوجو و بررسیهای لازم را انجام میدهد. پایگاههای اطلاعاتی PeptIdent و MassCot نیز از جمله پایگاههایی میباشند که پژوهشگران میتوانند جرمهای پپتیدی حاصل اسپکترومتری جرمی را در آنها جستوجو کنند. در زیر تعدادی از ابزارها و پایگاههای حوزه پروتئومیکس معرفی میشود. ابزارها کاربردهای متفاوتی دارند مثلاً X!Tandem یک ابزار بهمنظور شناسایی پروتئینها از میان انبوهی از پپتیدها است و یا ابزار Proteinlnfo توالیهای پروتئین را بهمنظور کشت اطلاعات آنالیز میکند.
۱۷۵-پروتئومیکس و ایمیونومیکس
۱-۲-۸ پایگاه SWISS-2DPAGE
پایگاه دادههای ژل الکتروفورز دو بعدی سوئیس (Swiss-2DPAGE database) در سال ۱۹۹۳ بنیان شد. این پایگاه توسط مرکز بیوانفورماتیک سوئیس اداره میشود. در نسخه جدید منتشر شده این پایگاه شامل نقشههای مرجع از نمونههای انسان و موش و همچنین از ساکارومایسیس سرویزیه و… بوده و به طور مستمر به روز میشود. شناسایی پروتئینها دراین پایگاه توسط چندین روش انجام میشود که عبارتند از مقایسه ژلها، میکروسکوئسینگ، ایمنوبلاتینگ، تجزیه و تحلیل ترکیب آمینواسیدی، انگشت نگاری پپتیدی که با استفاده از اسپکترومتری جرمی صورت میگیرد. میتوان ترکیبی از این روشها را نیز برای شناسایی استفاده کرد.
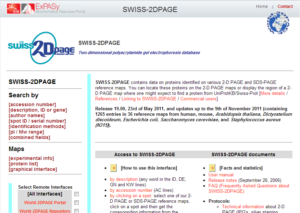
تصویر ۵-۸: نمایی از پایگاه SWISS-2DPAGE.
هسته اصلی این پایگاه شامل توضیحاتی درباره پروتئینهای شناسایی شده شامل: نقشههای تولید شده، اطلاعات فیزیولوژیکی و پاتولوژیکی مربوطه و دادههای آزمایشگاهی (نقطه ایزوالکتریک، جرم پپتیدی، وزن مولکولی، ترکیب آمینو اسیدی) و همچنین اطلاعات مربوط به مقالات و منابع مرتبط با پروتئینهای شناسایی شده است. در این پایگاه پیوندهای مرتبط با پایگاههای دیگر نیز وجود دارد. این پایگاه به آدرس http://world-2dpage.expasy.org/swiss-2dpage در دسترس است. و همچنین آسان ترین روش برای دسترسی به پایگاه اطلاعات SWISS-2DPAGE استفاده از سایت ExPASy است. برای دسترسی به دادههای SWISS-2DPAGE میتوان از ورودیهای متفاوتی استفاده کرد:
- نام پروتئین
- شماره دسترسی (Accession number)
- براساس توضیحات در مورد نویسنده یا مقاله
- کلیک کردن روی یک لکه
- داشتن شماره سریال لکه مورد نظر
ساختار دادههای ورودی SWISS-2DPAGE مشابهت زیادی با قالب دادههای ورودی SWISS-PROT دارد و فقط وجود اطلاعاتی مثل فهرست نقشهها و فهرست تصاویری که در آنها پروتئین مورد نظر شناسایی شده است این پایگاه را متفاوت ساخته است. همچنین اطلاعات مختلفی مانند روشهای نقشه برداری، همبستگی لکهها، ترکیب آمینو اسیدی، جرم پپتیدی حاصل از اسپکترومتری جرمی، میزان بیان پروتئین و تغییرات پس از ترجمه در این پایگاه موجود میباشد و دادههای تصویری مرتبط با هر پروتئین ورودی، جایگاه پروتئین انتخاب شده روی نقشه انتخابی (ژل دو بعدی) را نشان میدهد. ضمن این که اطلاعات تئوری pI و MW در مورد پروتئین مورد نظر نیز ازطریق تجزیه و تحلیلهای رایانه ای از توالی مربوطه استخراج شده است. صفحه نمایش اطلاعات در SWISS-2DPAGE حاوی اطلاعات و تصاویری از پروتئین مورد نظر ما میباشد که با کلیک کردن روی هر کدام از تصاویر میتوانیم اطلاعات را به صورت جزئی تر مشاهده کنیم.
۱۷۶-فصل هشتم
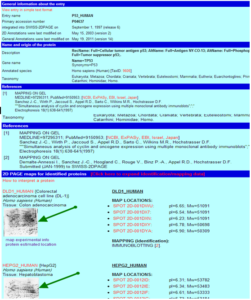
تصویر ۶-۸: یک نمونه نتیجه جستوجو در پایگاه SWISS-2DPAGE.
با کلیک بر روی هر کدام از تصاویری که در این پایگاه موجود میباشند تصویر بزرگتری مشاهده خواهید کرد که این تصاویر دارای نقاط قابل کلیکی هستند که با علامتهایی مشخص شدهاند. اگر روی هر کدام از این علامتها کلیک کنید، اطلاعات مربوط به لکه مورد نظر در صفحه جدیدی نمایش داده خواهد شد که شامل اطلاعات مختلف در مورد پروتئین مورد نظر و پیوندهایی به سایر پایگاههایی که دارای اطلاعات مرتبط هستند میباشد.
۱۷۷-پروتئومیکس و ایمیونومیکس
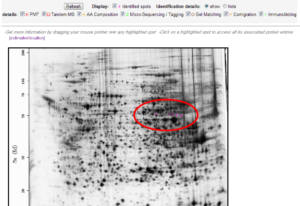
تصویر ۷-۸: نمایش ژل در پایگاه SWISS-2DPAGE. مناطقی که با علامتهای + نمایش داده شدهاند قابلیت کلیک دارند.
۲-۲-۸ پایگاه PeptideMass
پژوهشگران میتوانند توالی پروتئین مورد تحقیق خود را به همراه نام آنزیم برش دهنده اسیدآمینهها را در این نرم افزار وارد کنند تا این نرم افزار جرم پپتیدهایی که بر اثر برش آنزیمی ایجاد میشوند را به صورت نظری محاسبه کند. این نرم افزار میتواند برای تجزیه و تحلیل دادههای حاصل از اسپکترومتری مفید باشد. نرم افزار PeptideMass به آدرس http://web.expasy.org/peptide_mass در دسترس میباشد.در زیر دادههای جرمی این نرم افزار برای پروتئین P53 [Homo sapiens] را مشاهده میکنید.
۱۷۸-فصل هشتم

تصویر ۸-۸: نتیجه برش آنزیمی فرضی پروتئین P53توسط پایگاه PeptideMass.
۳-۲-۸ پایگاه PeptIdent
برای ساخت این پایگاه، جرمهای پپتیدی به دست آمده که به صورت نظری از تمام پروتئینهای موجود در پایگاههای SWISS-PROT/TrEMBL محاسبه شده و ذخیره شدهاند. در عمل، PeptIdent پایگاهی است که به کاربران این امکان را میدهد که با استفاده از دادههایی مانند pI، MW و اطلاعات مربوط به طیف جرمی یا انگشت نگاری پپتیدی پروتئین مورد نظر خود را شناسایی کنند. پایگاه PeptIdent امکان دسترسی به حجم وسیعی از دادههای ثبت شده در SWISS-PROT را به ما میدهد. زمانی که پپتیدهای فرضی از پایگاه SWISS-PROT تولید میشوند، توالیهای نشانه و پیش پپتیدها توسط PeptIdent قبل از محاسبه pI،MW یا جرم کل پروتئین و جرم پپتیدی حذف میشوند. این برنامه تغییرات پس از ترجمه و پیرایشهای مختلف را که در SWISS-PROT وجود دارد را در نظر میگیرد.
نتیجه جستوجو در این پایگاه دارای پیوند به FindMod،GlycoMod و FindPept است که به منظور به دست آوردن اطلاعات بیشتر در مورد ویژگیهای پروتئینهای یافت شده از جمله تغییرات پس از ترجمه، پیدا کردن جایگاههای برش اختصاصی و جرم پپتیدی است. ضمن این که برای هر پروتئین به دست آمده یک پیوند به BioGraph وجود دارد که نتایج PeptIdent را به صورت گرافیکی نشان میدهد. در عمل، انگشت نگاری بر اساس جرم پپتیدی شامل هضم یک پروتئین نامشخص با آنزیم پروتئیناز است. جایگاههای برش این آنزیم معلوم است و جرم پپتیدیهای به دست آمده توسط دستگاه اسپکترومتری جرمی خوانده و اندازهگیری میشوند. بنابراین حداقل دادهها ورودی برای جستوجو در این پایگاه شامل نام آنزیم پروتئاز و فهرستی از جرمهای پپتیدهای حاصل از هضم آنزیمی پروتئین مورد نظر است. نقطه ایزوالکتریک و وزن مولکولی موارد دیگری هستند که میتوان با استفاده از آنها جستوجو را اختصاصیتر کرد.
۱۷۹-پروتئومیکس و ایمیونومیکس
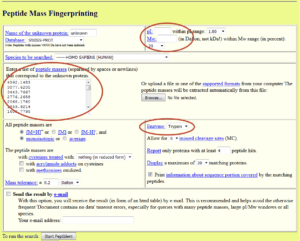
تصویر ۹-۸: نمایی از پایگاه PeptIdent. محل قرار دادن جرمهای پپتیدی در سمت چپ و منوی انتخاب نام آنزیم برش دهنده در سمت راست نمایش داده شده است.
نتیجه جستوجوی پپتیدها در PeptIdent به صورت فهرستی از پروتئینها بر اساس تعداد قطعات مشترک با پروتئین نامعلوم نشان داده میشود. بر این اساس میتوان پیش بینی کرد که پروتئین مورد نظر به احتمال زیاد همان پروتئینی است که دارای بیشترین تعداد قطعه مشترک است. دادههای جرمی پپتیدها را میتوان به عنوان نقطه شروعی برای بررسی تغییرات پسترجمهای و پردازش آن استفاده کرد. اگر پپتیدهای به دست آمده برای یک پروتئین هیچ گونه جفت مشخصی را در پایگاه مورد جستوجو نداشته باشد به احتمال زیاد پروتئین مورد نظر ما دارای تغییرات پس از ترجمه یا تغییرات مصنوعی یا قطع شدگی در حین توالییابی پروتئین باشد. در زیر یک نمونه از نتایج جستوجوی پایگاه PeptIdent آمده است.
۱۸۰-فصل هشتم
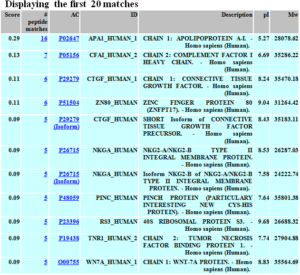
تصویر ۱۰-۸: یک نمونه نتیجه جستوجو در پایگاه PeptIdent.
۴-۲-۸ پایگاه دادههای جرمهای پپتیدی Masscot
Masscot نیز یک موتور جستوجوی بسیار قوی دیگر است که با استفاده از دادههای طیف جرمی به ما کمک میکند که پروتئین مربوطه را از پایگاه توالیهای اولیه شناسایی کنیم. در بسیاری از موارد این پایگاه مشابه پایگاه PeptIdent است ولی به دلیل خدمات منظم، این پایگاه مورد مراجعه بیشتری بوده است. این پایگاه به آدرس matrixscience.com/search_form_select.html در دسترس میباشد. در این موتور جستوجو جرم مولکولی در یک الگوریتم پنجره لغزان sliding window استفاده میشود. به همین دلیل در خروجی جستوجو به جای یک پروتئین تعدادی پروتئین با امتیازهای مختلف (از زیاد به کم) مرتب سازی میشوند.
انتخاب آنزیم: استفاده از آنزیمهایی که دارای اختصاصیت پایینی هستند به دلیل این که مخلوطی از آمینو اسیدهای آزاد، دی و تری پپتید را تولید میکنند مناسب نیست. این موضوع منجر به ترکیب پیچیده ای از تعداد زیاد قطعات دارای جرم مشابه میشود که در نتیجه آن پیکهای اسپکترومتری تداخل پیدا میکنند. بررسیهای بیشتر توسط آنالیز MALDI نشان میدهد که قطعات دارای جرم پایین تر از ۵۰۰ دالتن در ماتریس پیکها اشکال ایجاد میکنند. به همین دلیل مناسب تر است که از آنزیمهای دارای اختصاصیت حداقل برابر با تریپسین استفاده کرد.
برشهای از دست رفته (Missed Cleavages): اگر مطمئن باشیم که هضم آنزیمی ما بسیار دقیق و بدون تکههای ناقص (partial fragments ) است، تنظیم پارامتر missed cleavage روی عدد صفر باعث میشود که برشها محدود شود. اما اگر در حین آزمایش متوجه شویم که هضم آنزیمی ما همراه با تکههای فرعی شامل پپتیدهای با نقاط برش از دست رفته است باید این پارامتر را روی عدد ۱ یا ۲ برای تعداد جایگاههای از دست رفته تنظیم کنیم. باید از اعمال
۱۸۱-پروتئومیکس و ایمیونومیکس
عددهای بالاتر بدون دلیل خودداری کنیم. چرا که در این صورت جرم محاسبه شده برای پپتیدها که برای دادههای آزمایشگاهی استفاده میشوند بیشتر خواهند شد. در نهایت تعداد یافت شدههای تصادفی در نتایج بالا میرود و در نتیجه دقت جستوجوی ما پایین میآید.
انتخاب جرمهای جستوجو: باید از جرمهای آزمایشگاهی استفاده کرد که با اندازه کافی بزرگ باشند تا نتیجه جستوجو بین پپتیدها به خوبی صورت گیرد. در عین حال نباید آن قدر بزرگ باشد چراکه باعث افزایش پپتیدهای فرعی میشود. جرم مناسب برای آنزیم تریپسین بین ۱۰۰۰ تا ۳۵۰۰ دالتن است.
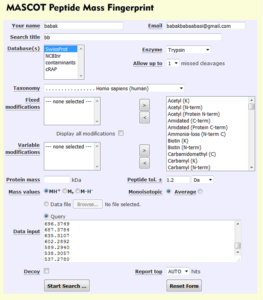
تصویر ۱۱-۸: نمایی از پایگاه دادههای جرمهای پپتیدی Masscot.
در تصویر ۱۲-۸ یک نمونه از دادههای خروجی Masscot را مشاهده میکنید.در بخش اول پروتئینی که بیشترین امتیاز را آورده است نمایش داده میشود و در ادامه لیست تمام پروتئینهایی که میتوانند به داده ما نزدیک باشند لیست میشوند. با کلیک بر روی نام هر پروتئین به اطلاعات بیشتری میتوان دست یافت.
۱۸۲-فصل هشتم
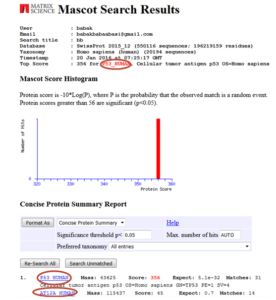
تصویر ۱۲-۸: نتیجه جستوجو در پایگاه دادههای جرمهای پپتیدی Masscot.
۳-۸ شناسایی تغییرات پس از ترجمه
بعد از آن که نوع پروتئین شناسایی شد معمولا محققین علاقمند هستند تا تغییرات پس از ترجمه پروتئین مورد نظر خود را نیز بدانند. حدود ۲۰۰ نوع تغییر پس از ترجمه تا به حال برای پروتئینها شناسایی شده است که در اغلب موارد برای عملکرد پروتئینها ضروری هستند. این تغییرات ممکن است ساختار پروتئین، انحلال، فعالیت زیستی، جایگاه فعال و ارتباط با پروتئینهای دیگر را تحت تاثیر خود قرار دهد. تعدادی از این تغییرات به طور مستقیم با روش SDS-PAGE قابل تشخیص هستند. به عنوان مثال فسفوریلاسیونها و کربوکسیلاسیونها و.. باعث میشوند که حرکت پروتئین در ژل تغییر کند و باندهایی ایجاد شود که دارای جرم مولکولی متفاوتی هستند. در یوکاریوتهای پیشرفته یک سوم پروتئینها فسفریله هستند و همچنین نیمی از پروتئینها در انسان گلیکوزیله (اضافه شدن منوکربوهیدرات به پروتئین) میشوند. پروتئینهای غشایی خاص با چسبیدن اسیدهای چرب به آنها دچار تغییر میشوند. تعدادی از پروتئینها همچون انسولین یا ایمونوگلوبین با تشکیل پیوندهای دی سولفیدی مابین زیرواحدهای مختلف پایدار میشوند. علاوه بر این،تعدادی از پروتئینها یوبیکوئیتینه میشوند.با اضافه شدن یوبیکوئیتین به پروتئین، آن پروتئین از طریق سیستم پروتئاز از بین میرود. در بعضی از پروتئینها ممکن است در اثر تبدیل یک آمینو اسید به یک آمینو اسید دیگر تغییر صورت بگیرد،مثلا تبدیل آرژنین به سیترولین. گاهی در پروتئینهای خاص ممکن است یک قسمت از پروتئین به نام اینتئین از پروتئین جدا شود که این اتفاق پیرایش پروتئین نام دارد. فراوانترین تغییرات در پروتئینها فسفوریلاسیون،گلیکوزیلاسیون و یوبیکوئیتیناسیون است. تشکیل پیوندهای دی سولفیدی فراوانی زیادی در سلول ندارد اما از ابزارهای بیوانفورماتیکی که برای بررسی نواحی که دچار پیوندهای دیسولفیدی میشوند میتوان به برنامه Systeines اشاره کرد.
۱۸۳-پروتئومیکس و ایمیونومیکس
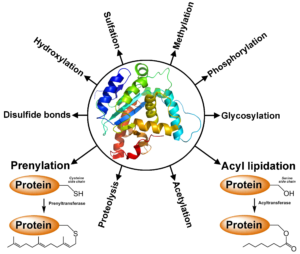
تصویر ۱۳-۸: انواع تغییرات پس از ترجمه.
هم اکنون، آنتیبادیهایی وجود دارند که برای شناسایی اپی توپهای ویژهای مانند جایگاههای فسفریلاسیون طراحی شدهاند. همچنین نشاندار کردن توسط فسفات رادیو اکتیو روش بسیار حساسی برای مشاهده فسفریلاسیون است. چند روش برای رویت گلیکولیزاسیون پروتئینها مانند تیمارهای شیفت، لکتین و آنتیبادیها طراحی شدهاند.
فسفوریلاسیون پروتئین به معنی اضافه شدن یک یا چند گروه فسفات به آمینو اسید خاص در پروتئین است. در سلولهای پستانداران گروه فسفات به آمینو اسیدهای آسپارتات، گلوتامات و هیستیدین فسفریله میشود.گاهی اوقات فسفوریلاسیون روی آرژنتین، لیزین و سیستئین پروتئین نیز اتفاق میافتد. فسفوپروتئومیکس در حقیقت مطالعه پروتئینهای درگیر در فرایند فسفوریلاسیون است. با فسفوپروتئومیکس میتوان اطلاعاتی در مورد تعداد زیادی از پروتئینها و مکانهای فسفوریلاسیون مختلف آنها در هر بار آزمایش به دست آورد. معمولترین روش برای آزمایشهای فسفوپروتئومیکس برچسب زدن تمایلی کد شده با ایزوتوپ فسفوپروتئین (phIAT)، برچسب زدن تمایلی کد شده با ایزوتوپ (ICAT) و نشان دار کردن ایزوتوپ پایدار در محیط کشت است. در روش برچسب زدن تمایلی کد شده با ایزوتوپ فسفو پروتئین مستقیما ایزوتوپ را به داخل فسفوسرین یا فسفوترئونین وارد میکنند. از روش phIAT و ICAT برای نشان دار کردن پروتئینها در محیط آزمایشگاه استفاده میشود در حالی که از روش SILAK برای نشان دار کردن پروتئینها در موجود زنده استفاده میشود. روش SILAK برای نشان دار کردن پروتئینها در کشتهای سلولی که تحت شرایط مختلف رشد میکنند مفید است. از ابزارهای بیوانفورماتیکی که برای مشخص کردن نواحی که دچار فسفریلاسیون میشوند میتوان به Automotif با روش SVM اشاره کرد. توسط روشهای آزمایشگاهی مختلفی میتوان فسفاته شدن پروتئین را مشخص کرد که از جمله این روشها میتوان به روش IMAC کروماتوگرافی (Immobilized metal affinity chromatography)، Chemical tagging و Immuno – precipitation اشاره کرد.
گلیکوزیلاسیون یک تغییر بسیار مهم بعد از ترجمه در پروتئینها است.گلیکوزیلاسیون پروتئین به معنی اضافه شدن کربوهیدرات به پروتئین است. در سلولهای پستانداران ۵۰ درصد از پروتئینها به صورت گلیکوزیله وجود دارند. گلیکوزیلاسیون اعمال مهم پروتئینها در سلولها را کنترل میکند که عبارتند از پایداری،لنگراندازی، برهمکنش سلول به سلول،ترشح و بسیاری از عوامل دیگر. به پروتئینهای گلیکوزیله ای که جز اصلی آنها کربوهیدرات باشد پروتئوگلیکان میگویند. در گلیکوپروتئین بخش کربوهیدراتی به طور کوالان به آمینو اسیدهای آسپاراژین، سرین و ترئونین متصل میشود.
۱۸۴-فصل هشتم
با توجه به اهمیت گلیکو پروتئینها در مدیریت بیماریهای انسانی با ایمونوتراپی و دارو و همچنین به علت این که گلیکو پروتئینها مارکر چندین نوع سرطان میباشند گلیکوپروتئینهای مختلف خیلی مورد توجه قرار گرفتهاند. در گلیکو پروتئومیکس چندین روش برای بررسی ساختمان آنها از جمله ماهیت پروتئینها،گلیکوزیلاسیون آنها و مکان اتصال مونومرهای کربوهیدارت خاص یا پلیمرها توسعه داده شده است. در این روشها از غنی کردن گلیکو پروتئینها به کمک کروماتوگرافی تمایلی و سپس شناخت ماهیت پروتئینهای کربوهیدراتهای متصل به آنها به کمک طیف سنجی استفاده میشود. از ابزارهای بیوانفورماتیکی که برای بررسی نواحی که دچار گلیگوزیلاسیون میشوند میتوان Gly Mod را نام برد.از روشهای آزمایشگاهی برای شناسایی بنیان قندی روی پروتئین میتوان به کروماتوگرافی HPAEC-PAD اشاره کرد.
یوبیکوئیتین یک پروتئین کوچک و تا حد زیادی حفاظت شده است که انحصارا در یوکاریوتها یافت میشود. یوبیکوئیتیناسیون به معنی اضافه شدن یوبیکوئیتین به پروتئینهایی است که طول عمرشان تمام شده، بد ترجمه شدهاند، یا تحت شرایط خاص عملکردشان را از دست دادهاند به علت این اتفاق پروتئین برای پروتئولیز به کمپلکس پروتئازوم منتقل میشود. نقص در روند یوبیکوئیتیناسیون باعث بیماری آلزایمر،پارکینسون، بیماریهای خود ایمنی و سرطان میشود.
یوبیکوئیتومیکس اولین بار در مخمر مورد مطالعه قرار گرفت. پنگ و همکارانش ژن یوبیکوئیتین را کلون کردند که در ابتدای آن یک دنباله ۶ هستیدینی متصل بود. ژن کلون شده مزبور را به مخمر فاقد یوبیکوئیتین منتقل کردند که مخمر توانست پروتئینهای یوبیکوئیتین با شش هیستیدین اضافه تولید کند. یوبیکوئیتین همراه آنزیم متصل کننده و پروتئینهای هدفی که باید تخریب شوند به وسیله کروماتوگرافی تمایلی روی ستون نیکل خالص سازی شدند. و سپس پپتیدهای حاصل از هضم تریپسینی پروتئینهای متصل به یوبیکوئیتین به وسیله طیف سنجی جرمی بررسی و در نهایت به کمک توالی پروتئین موجود در بانک اطلاعاتی پروتئین مقایسه و شناسایی شدند. به کمک این روش پنگ و همکارانش حضور بیش از ۱۰۰۰ مکان یوبیکوئیتیناسیون را در بین ۷۲ جفت پروتئین یوبیکوئیتین در مخمر مشخص کردند.
پروتئینها علاوه بر فسفوریلاسیون،گلیکوزیلاسیون و یوبیکوئیتیناسیون متحمل چندین تغییر دیگر نیز میشوند.تعدادی از این تغییرات عبارتند از: پروتئولیز (باعث کوتاه تر شدن پروتئین میشود)، متیلاسیون (گروه متیل به لیزین تعدای از پروتئینها متصل میشود)، سولفوناسیون (در تعدادی از پروتئینها مانند گاسترین،گروه سولفات به تیروزین آنها اضافه میشود)، پرنیلاسیون (در پروتئینهای خاص نظیر Ras و ترانسدوسین گروههای ایزوپرنوئید به سیستئین آنها اضافه میشود)، سامویلاسیون (به معنی اضافه کردن پروتئینهای کوچک به مولکول پروتئین است)، آمیداسیون (گروه آمید به گلیسین انتهایی c-ترمینال تعدادی از هورمونهای پروتئینی اضافه میشود)، هیدروکسیلاسیون و کربوکسیلاسیون (در هیدروکسیلاسیون پروتئین خاص، گروه هیدروکسیل به پرولین و لیزین اضافه میشود.) و لیپیداسیون (در پروتئینهایی که فاقد دمین ترانسمنبران هستند معمولا اضافه شدن مولکول لیپید به انتهای c-ترمینال اتفاق میافتد.).
روش MS نیز ابزاری قوی در شناسایی و تایید تغییرات پس از ترجمه محسوب میشود. با این روش پس از برش پروتئین خالص شده و خواندن جرم مولکولی پلیپپتیدهای حاصل، نتایج تجربی با دادههای تئوری مورد مقایسه قرار میگیرد. در این صورت پپتیدهای دارای تغییر در جرم مولکولی شناسایی میشوند. سپس با مراجعه به پایگاههای اطلاعاتی تغییرات پس از ترجمه مانند FindMod میتوان تغییر احتمالی را پیشگویی نمود. از جمله پایگاههای بررسی تغییرات پس از ترجمه میتوان به FindMod،RESID،GlycoMod و FindPept اشاره کرد که به منظور به دست آوردن اطلاعات بیشتر در مورد ویژگیهای پروتئینهای یافت شده از جمله تغییرات پس از ترجمه، پیدا کردن جایگاههای برش اختصاصی و جرم پپتیدی به پژوهشگران کمک میکنند. همچنین ابزاری به نام Signal P وجود دارد که به پیش بینی حضور و محل سایتهای پپتید سیگنالها در توالی اسید آمینهها در موجودات مختلف میپردازد.
پایگاه دادههای جرمهای پپتیدی FindMod
FindMod به آدرس www.expasy.org/tools/findmod امکان دسترسی به دادههای ژنومی، اسپکترومتری و ژلهای الکتروفورزی با وضوح بالا توانایی شناسایی صدها پروتئین موجودات مختلف و یا انگشت نگاری پپتیدی را به ما میدهد. با این حال، توجه کمتری به استفاده از این اطلاعات در شناسایی اصلاحات پس از ترجمه پروتئینها شده است. پایگاه FindMod حاوی اطلاعات بسیاری از اصلاحات پس از ترجمه است. ابزار موجود در این پایگاه امکان بررسی تفاوت بین جرم پپتیدها براساس دادههای تجربی و محاسبات تئوری را میدهد. زمانی که اختلاف جرم به دلیل اصلاحات پس از ترجمه باشد، قوانین هوشمندانهای توسط این ابزار برای شناسایی آمینواسیدهای دارای اصلاحات به کار میرود.
قوانین FindMod بر اساس تجزیه و تحلیل ۵۱۵۳ اصلاحات پس از ترجمه استخراج شدهاند که در پایگاه دادههای SWISS-PROT برای پروتئینها ثبت شده است. بر این اساس بیش از ۲۲ تغییر پس از ترجمه شناسایی و گروه بندی شدهاند. بر اساس این تغییرات ۲۹ قانون استخراج شده است. بر اساس این قوانین FindMod توانایی شناسایی انواع تغییرات را در انتهای آمینی, کربوکسیلی یا در خلال پروتئین دارد. برای پیش بینی و استخراج قوانین، FindMod از تغییرات ثبت شده
۱۸۵-پروتئومیکس و ایمیونومیکس
در SIWISS-PROT به همراه دادههای موجود در PROSITE و دادههای موجود در مقالات تغییرات جدید و اثر آنها در جرم پپتیدی استفاده شده است. FindMod به ما این امکان را میدهد که اصلاحات پس از ترجمه در پروتئین مورد نظر با مقایسه بین جرم به دست آمده آزمایشگاهی و جرم محاسبه شده به صورت تئوری را شناسایی کنیم. اگر تفاوت مربوط به اصلاحاتی شناخته شده باشد که قبلا در SWISS-PROT ثبت نشده باشد. قوانین هوشمند موجود برای شناسایی و پیش بینی نوع و آمینو اسید اصلاح شده استفاده میشود.
پارامترهای که در اطلاعات ورودی مورد توجه هستند:
- توالی پروتئینی
- فهرست جرمهای پپتیدی
- تغییرات پس- ترجمه ای تعریف شده توسط کاربر
- تعیین نوع یونها
- تنظیم ایزوتوپها
- تیمار شیمیایی اسیدهای آمینهها
- دامنه تغییرات جرمی
- آنزیمها
- نقاط برش از دست رفته
- مرتب سازی پپتیدها در جدول نتایج
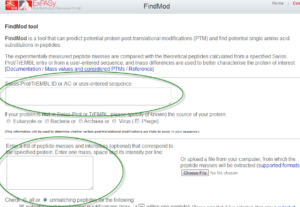
تصویر ۱۴-۸: نمایی از پایگاه FindMod. کاربر میتواند در کادر بالا توالی و یا نام پروتئین را وارد کند و همچنین کادر پایین به منظور وارد کردن جرمهای پپتیدی پروتئین مورد بررسی میباشد.
۱۸۶-فصل هشتم
نتایج FindMod
FindMod گزارشی را به صورت یک سری جداول ارائه میکند. این جداول شامل پپتیدهایی است که جرم آنها با جرم پپتیدهای فرضی (دارای اصلاحات پس از ترجمه ای یا بدون آن) جور بوده است. توالیهای سیگنالی و توالیهای نشانه قبل از محاسبه ی جرم و برشهای فرضی از توالی مورد نظر حذف میشوند.
جدول اول نتایجی را گزارش میدهد که با هضمهای فرضی دارای این شرایط یافت شده باشند: بدون تغییر،داری تغییر ثبت شده در SWISS-PROT، دارای تغییرات شیمیایی که توسط کاربر هنگام ورود دادهها انتخاب شده است. جدول دوم حاوی پپتیدهایی است که از ورودیهای کاربر هستند ولی با هیچ کدام از پپتیدهای فرضی تولید شده در پایگاه حتی با در نظر گرفتن اصلاحات پس از ترجمه جور نشدهاند. در مورد این پپتیدها FindMod با استفاده از قوانینی پیش بینی میکند که احتمال وجود چه نوع اصلاحاتی در توالی مورد جستوجو باعث جور نشدن آنها شده است. جدول سوم حاوی تک جایگزینیهای آمینو اسیدی است که توسط تفاوتهای جرمی شناسایی میشوند. در انتهای صفحه خروجی پپتیدهایی که حتی با استفاده از پارامترهای ذکر شده هیچ پپتیدی برای آنها پیدا نشده است به صورت جداگانه نشان داده میشوند.
۱۸۷-پروتئومیکس و ایمیونومیکس
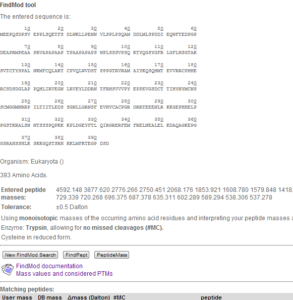
تصویر ۱۵-۸: بخش اول نتیجه جستوجو در پایگاه FindMod.
۱۸۸-فصل هشتم
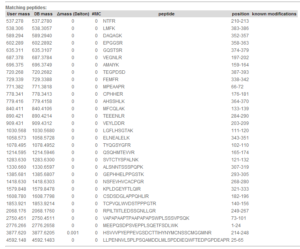
تصویر ۱۶-۸: بخش دوم جستوجو در پایگاه FindMod.
۴-۸ معرفی برخی از ابزارهای پروتئومیکس
BLink: نتایج جستوجوهای BLAST را که برای هر پروتئین انجام شده، به همراه اطلاعات مربوط به دمینها را در Entrez Proteins نمایش میدهد.
CD Search: امکان جستوجوی دمینهای حفظ شده در یک پروتئین را فراهم خواهد کرد.
CDART: هنگامی که یک توالی پروتئین را وارد میکنیم، دمینهای عملکردی و فهرست پروتئینها با دمینهای مشابه را نشان میدهد.
OMSSA[۱]: سرویس جستوجوگر OMSSA به پژوهشگران پروتئومیکس این امکان را میدهد که جرم[۲] پپتیدها و پروتئینها را برای تشخیص ارایه دهند، سپس این اطلاعات را با یونهای تئوریکی حاصله از کتابخانههای داده توالیهای پروتئینی شناخته شده، مقایسه کرده و نتایج را با استفاده از یک امتیاز حاصل از آزمون فرضی کلاسیک رتبهبندی[۳] میکند.
TaxPlot: ابزاری است برای مقایسهی سه جهتهی ژنومها براساس توالیهای پروتئینی که آنها را رمز کنند. برای استفاده TaxPlotهر شخص باید یک منبع ژنومی را با دو ژنوم دیگر که مقایسه شدهاند، انتخاب کند.
Cn3D: ابزاری است برای نمایش سه بعدی و در برنامهی ویندوز، Macintosh و Unix قابل اجرا است.
VAST Search: جستوجوگر VAST سرویس جستوجوی تشابه ساختار- ساختار NCBI است. این برنامه مقایسهی ساختارهای سه بعدی یک پروتئینی که تازه ساختارش مشخص شده را با ساختارهای موجود در پایگاه اطلاعاتی MMDB/PDB انجام میدهد.
[۱]-Open Mass Spectromrtry Search Algorithm
[۲]-Mass
[۳]-Ranks
۱۸۹-پروتئومیکس و ایمیونومیکس
۵-۸ دستهبندی و جابجایی پروتئینها
مطالعه ساز و کار انتقال پروتئینها Protein Sorthing نامیده میشود. بسیاری از پروتئینها بعد از ترجمه به اندامکهای دیگری منتقل میشوند که این انتقال توسط پپتیدهای نشانه هدفمند میشود. طول توالیهای نشانه متفاوت است و از ۸ تا ۲۰ اسیدآمینه در پپتیدهای نشانه میتوکندریایی تا ۱۰۰-۲۵ اسیدآمینه در پپتیدهای نشانه کلروپلاستی متفاوت است.از برنامههایی که مکانیابی پروتئینها را انجام میدهند میتوان به WOLF-P SORT و Signalp اشاره کرد.
۶-۸ برهمکنش پروتئین با پروتئین (اینتراکتوم)
بسیاری از پروتئینها برای انجام فعالیتهای عملکردی خود با یکدیگر میانکنش میکند. در روشهای آزمایشگاهی اثرات متقابل بین پروتئینها با استفاده از روش کلاسیک دورگهسازی دوگانه مخمر انجام میشود (Yeast two hybrid). یکی دیگر از روشهای پرکاربرد کروماتوگرافی جذبی ستونی است. از منظر زیستشناسی برهمکنش میان پروتئینها زمانی رخ میدهد که دو یا چند پروتئین با همکاری هم عملکرد زیستی خاصی را انجام دهند. بسیاری از فرایندهای مولکولی در سلولها مانند همانندسازی، میتواند حاصل همین برهمکنشها میان پروتئینها باشند. بهطور کلی میتوان شبکه برهمکنش میان پروتئینها را به صورت سیستمی پیچیده از پروتئینهایی که توسط برهمکنشها با هم ارتباط دارند، تعریف کرد. دادههای زیستی را میتوان به صورت شبکه و گراف نمایش داد. دو شبکه برهمکنش پروتئینها، به این علت که فقط حضور یا عدم حضور برهمکنش بین دو پروتئین خاص بدون در نظر گرفتن جهت برهمکنش، بررسی میشود، یالها در این شبکهها بدون جهت هستند، در مقابل، شبکههای تنظیم بیان ژن جهتدار هستند، به این دلیل که در پروسه تنظیم بیان ژن، محصول بیان ژن، بیان ژن دیگری را تحت کنترل دارد.
بعد از توسعه و پیشرفت در زیست شناسی سیستمها، این دیدگاه که یک واکنش بیوشیمیایی صرفا به وسیله یک آنزیم کاتالیز میشود دستخوش تغییر شده است. دیدگاه جدید این است که گروهی از پروتئینها در مسیر سوخت و سازی در برهمکنش با هم هستند.این رویکرد جدید منتهی به شناخت شبکه پروتئینها و مفهوم انتراکتومها شده است. به انتراکتومها کمپلکسوزوم نیز گفته میشود چون آنها متشکل از تعداد زیادی پروتئین در مسیر سوخت و سازی مختلف هستند. بررسی انتراکتومها یک بخش اساسی شناخت برهمکنش و عملکرد پروتئینها را تشکیل میدهد. شناخت کامل برای شناخت همه روندهای سوخت و سازی ضروری است. علاوه بر این درک بهتر انتراکتومها برای شناخت بیماریها و توسعه داروها حیاتی است. چون بیماریها و توسعه داروها هر دو به تغییرات ایجاد شده در مسیرهای سوخت و سازی مرتبط هستند و به وسیله تعدادی پروتئین که با هم فعالیت میکنند کنترل میشوند.شناخت نسبتا کاملی از انتراکتومها در مخمر وجود دارد.
تعاملات بین پروتئینها برای اکثر عملکردهای زیست شناختی مهم هستند. به عنوان مثال، سیگنالهای سطح خارجی یک سلول توسط تعامل پروتئینی بین مولکولهای سیگنالی به داخل سلول هدایت میشوند. این فرایند را انتقال سیگنال مینامند که نقش اساسی در بسیاری از فرایندهای بیولوژیکی و در بسیاری از بیمارها (به عنوان مثال سرطان) بازی میکند. پروتئینها ممکن است برای مدت طولانی به شکل بخشی از یک کمپلکس پروتئینی در تعامل باشند. یک پروتئین ممکن است در حال حمل یکی دیگر از پروتئینهاباشد. (برای مثال، از سیتوپلاسم به هسته و یا بالعکس به وسیله ایمپورتین منافذ هستهای)، و یا بهطور خلاصه یک پروتئین ممکن است با یک پروتئین دیگر تعامل داشته باشد فقط برای اینکه آن را تغییر دهد (برای مثال، پروتئین کیناز یک فسفات را به پروتئین هدف اضافه میکند).
۱-۶-۸ روشهای بررسی تعامل پروتئین-پروتئین
تعاملات پروتئینها آنقدر مهم هستند که روشهای بسیاری برای تشخیص آنها وجود دارد. هر روش میتوان با توجه به حساسیت و ویژگیهایی خود دارای نقاط ضعف و قوت میباشد. روشهایی از قبیل مخمر دو هیبرید غربالگری برای تشخیص تعامل پروتئینها میتوانند مورد استفاده قرارگیرند. همچنین بسیاری از روشهای زیستفیزیکی برای بررسی ماهیت و خواص تعاملات موجود هستند. از لحاظ تئوری غالباً از نظریه گراف برای مدل کردن تعامل دادههای بزرگ تجربی استفاده میکنند. برای درک برهمکنش پروتئینها در شرایط آزمایشگاهی و در موجود زنده،روشهای پیشرفته ای وجود دارد که به صورت دسته بندی شده در جدول زیر آمده است.
جدول ۱-۸: انواع روشهای بررسی برهمکنش پروتئینها.

۱۹۰-فصل هشتم
روشهای شناسایی تعامل پروتئینها صدها هزار تعامل را تعریف کردهاند. این تعاملات در پایگاههای تخصصی بیولوژیکی جمع شدهاند که امکان مطالعه بیشتر و مونتاژ تعاملات را فراهم میکند. اولین پایگاه داده تعامل پروتئینی DIPبود و از آن زمان پایگاه دادههای بیشتری از تعامل پروتئینها ایجاد شدهاست از جمله BioGRID و STRING.
- پایگاه دادههای اصلی بر اساس نتایج گسترده عملی به دست آمده است. مانند: مرجع پروتئین انسانی HPRD.
- پایگاه داده تخمینی بر اساس ابزارهای محاسبات بدست آمده است. مانند OPHID و STRING.
در روش بررسی برهمکنش پروتئینها به وسیله کامپیوتر بررسی محاسباتی روی دادههای موجود در بانکهای اطلاعاتی ژن و پروتئین انجام میشود. این رویکرد مبتنی بر مقایسه تطابقی قطعات اسید نوکلئیک خاص،پروتئینهای کد شده، یا دمینهای پروتئینی در بانکهای اطلاعاتی است.عمومیترین روش Rosetta stone است که توسط مارکوت و همکارانش توسعه داده شده است.رویکرد مزبور بر اساس این فرضیه است که پروتئینهای برهمکنش کننده خاص ممکن است در کنار هم به صورت یک پروتئین ادغامی به نام پروتئین روزتا استون وجود داشته باشند. پروتئینهای روزتا استون به کمک آنالیز بانک اطلاعاتی پروتئین شناسایی میشوند و برای ساختن شبکه پروتئینی یا انتراکتومها مورد استفاده قرار میگیرند. به عنوان مثال بعد از جستوجوی بانک اطلاعاتی اگر پروتئین A و پروتئین B به صورت یک پروتئین تکی ادغامی در تعدادی از موجودات زنده وجود داشته باشند،آنگاه ممکن است به عنوان پروتئینهای برهمکنش کننده در نظر گرفته شوند. از برنامه کامپیوتری برای جستوجوی حضور پروتئین روزتا در موجودات زنده خیشاوند استفاده میشود، در صورت پیدا شدن پروتئین روزتا میتوان فهمید که پروتئینهای مورد نظر با هم برهمکنش دارند. با استفاده از اطلاعات موجود در مورد پروتئین روزتا میتوان شبکه برهمکنش یا انتراکتوم راساخت.از چندین روش محاسباتی دیگر نیز میتوان برای ساخت شبکه پروتئینهای برهمکنش کننده استفاده کرد. بعضی نکات،ابزارها و روشها در زیر به صورت خلاصه آورده شدهاند.
– روشهای با بازده بالا معمولا تعداد زیادی برهمکنش مثبت کاذب دارند.
– روش پربازده مخمر دورگه ۵۰% قابل اطمینان است. همچنین تعداد زیادی برهمکنش منفی کاذب دیده میشود.
– دو پروتئین با عملکرد متفاوت بارها با هم برهمکنش دارند. چنین برهمکنشهایی یالهای تصادفی بین گروههای عملکردی در شبکه واکنش به وجود میآورد.
– ابزاریهای متنوعی، مانند Cytoscape، RINalayzer و RING برای ساخت، مشاهده و آنالیز شبکههای پروتئینی ساخته شدهاند. RING و RINaLazer مختص ساخت شبکههای برهمکنش آمینواسیدی میباشند.
– هابها آن دسته از پروتئینها هستند که علاوه بر دارا بودن درجه بالا نسبت به سایر پروتئینها در شبکه، تمایل کمی به برقراری برهمکنش با همدیگر دارند.
– I-TASSER پلت فرمی برای پیشگویی ساختار و عملکرد پروتئین است.
– ارزیابی انتقادی از پیشبینی ساختار پروتئین؛ CASP، یک مجمع جهانی گسترده برای پیشبینی ساختار پروتئین است و هر دو سال یکبار از سال ۱۹۹۴ به صورت سراسری، تحت نظارت بنیانگذار این برنامه، برگزار میشود و بهترین ابزارها و الگوریتمهای پیشبینی پروتئین را معرفی میکند.
– RINerator نرمافزاری برای تبدیل یک پروتئین به گراف میباشد و برای استفاده از این نرم افزار باید مراحل زیر را طی کنید.
مرحله اول استفاده از نرم افزار Reduce میباشد که اتمهای هیدروژن به کمک این نرمافزار افزوده میشود. چون فایلهای PDB فاقد اتم هیدوژن هستند. مرحله دوم استفاده از نرم افزار Probe میباشد که پیوندهای غیر کوالان توسط این نرمافزار شناسایی میشوند و در نهایت توسط RINerater شبکه ساخته میشود.
– Netcentra نرمافزاری است که معیارهای مرکزیت را بررسی میکند و معیارهای مرکزیت یکی از راههای مقایسه شبکهها میباشد که در فصل سیستم بیولوژی با این مفاهیم آشنا خواهید شد.
۲-۶-۸ روشهای پیشبینی اثرات متقابل پروتئینها
۱- پیشبینی اثرات متقابل بین Proها براساس ترکیب دمینی
مبتنی بر اتفاقات ترکیب ژنی است اگر دو دومین در دو ORF جدا باشند و در یک موجود دیگر در یک ORF باشند.
۲- پیشبینی اثرات متقابل بین پروتئینها براساس همسایگی ژنی
اگر پیوستگی ژنی معینی پیدا شود (اپران) از نظر عملکردی این پروتئینها با هم ارتباط دارند.
۳- پیشبینی اثرات متقابل بین پروتئینها براساس همولوژی توالیها
اگر جفت پروتئینی در یک پروتئوم اثرات متقابل داشته باشد شاید در پروتئوم دیگر هم همان اثرات را داشته باشند.
۴- پیشبینی اثرات متقابل بین پروتئینها براساس اطلاعات فیلوژنی
با استفاده از پروفایلهای فیلوژنی که به عنوان الگوهای جفت ژنی که به طور همزمان در ژنومهای مختلف غایب یا حاضرند انجام میشود.
۵- پیشبینی اثرات متقابل بین پروتئینها براساس روشهای ترکیبی
STRING برنامهای است که ژنها یا پروتئینهای مرتبط را براساس ترکیبی حاصل از پیوستگی ژن، اتحاد ژنی، پروفایلهای فیلوژنی پیشبینی میکند.
۱۹۱-پروتئومیکس و ایمیونومیکس
STRING برنامهای است که ژنها یا پروتئینهای مرتبط را براساس ترکیبی حاصل از پیوستگی ژن، اتحاد ژنی، پروفایلهای فیلوژنی پیشبینی میکند.
۳-۶-۸ انتراکتومها
در زیست شناسی مولکولی، یک interactome مجموعه ای کامل از فعل و انفعالات مولکولی در یک سلول خاص است. این اصطلاح به طور خاص به فعل و انفعالات فیزیکی میان مولکولها اشاره دارد (مثلا فعل و انفعالات پروتئین پروتئین) اصطلاح interactome همچنین میتواند مجموعه ای از فعل و انفعالات غیر مستقیم میان ژنهارا نیز توصیف کند. بیشتر پروتئینها به صورت کمپلکس هستند. چند کمپلکس با هم میتوانند اعمال سلولی متفاوتی را در موجود زنده به عهده داشته باشند. این اعمال ممکن است در مسیرهای متابولیکی مختلف، ارتباط سلول به سلول از جمله، پیامدهی، همانندسازی DNA، رونویسی، ترمیم و نوترکیبی،تقسیم سلولی و رشد نقش داشته باشند. به کمپلکسهای پروتئینی فوق انتراکتوم یا کمپلکسزوم[۱] گفته میشود.
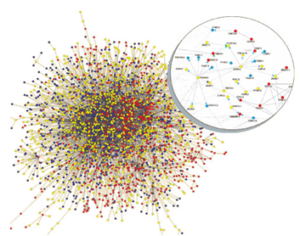
تصویر ۱۷-۸: نمایش یک نمونه interactome.
انتراکتومها یا نقشههای برهمکنش پروتئین با پروتئین در تعدادی از موجودات زنده از جمله ویروسها، باکتریها و چند سلول یوکاریوت نظیر مخمر، نماتد، مگس، موش، انسان و گیاهان خاص بررسی شده است. بسیاری از موجودات زنده ذکر شده، موجودات زنده مدل هستند که بیوشیمی، ژنتیک و زیستشناسی مولکولی در آنها تا حدی مشخص شده است. مطالعه انتراکتومها برای تعیین عملکرد ژن و تنظیم آنها مفید است. به علاوه مطالعه نقشههای برهمکنش پروتئین با پروتئین مبنایی برای درک پیچیدگی موجودات زنده مختلف را فراهم میکند که با تغییر ساده در تعداد ژنها نمیتواند تفسیر شود. به نظر میرسد که پیچیدگی یک موجود زنده وابسته به تعداد برهمکنش پروتئین با پروتئین است و یک موجود زندهی پیچیده نظیر انسان دارای برهمکنش پروتئین با پروتئین بیشتری نسبت به مخمر، مگس و نماتد است. مطالعه انتراکتومها نشان داد که نه تنها ژنها و پروتئینها بلکه انتراکتومها نیز طی تکامل موجود زنده حفاظت شدهاند.
۴-۶-۸ انتراکتومهای پروکاریوتی
در سالهای اخیر نقشههای برهمکنش پروتئین با پروتئین چند باکتری و چند ویروس بررسی شده است. از بین آنها انتراکتوم اشیرشیاکلی بیشتر از بقیه شناخته شده است. در پروکاریوتها، اشیرشیاکلی از نظر بیوشیمی، ژنتیک و فیزیولوژی بهتر شناخته شده است. مطالعات اولیه در مورد این باکتری (کشف پدیده آمیزش در اشیرشیاکلی)، زیستشناسی مولکولی را متحول ساخته است. مطالعهی باکتری مزبور در نهایت منجر به توسعهی روشهای کلونینگ مولکولی از طریق فناوری نوترکیب شد که این به نوبه خود طلایهدار عصر ژنومیک شد. با به کارگیری سنجش دو هیبریدی مخمر، تقریباً ۴۰۰۰ پروتئین در اشیرشیاکلی پیدا شده که با حدود ۲۷۰۰ پروتئین در اشیرشیاکلی برهمکنش دارند. این برهمکنشهای پروتئین با پروتئین شامل مسیرهای متابولیکی مختلف در این موجود زنده است. هلیکوباکترپیلوری[۲] باکتریی است که به طور وسیع مطالعه شده است. این باکتری در ۵۰ درصد از بیماریهای مربوط به انسان که موجب عفونت لایه گاستریک میشود، یافت شده است؛ همچنین باعث چندین بیماری از جمله زخمهای معده و حتی سرطان در انسان میشود. بیش از ۲۶۰ پروتئین پیلوری که مشارکت در بیش از ۱۲۰۰ برهم کنش پروتئین با پروتئین دارند، به کمک سنجش دو هیبریدی مخمر بررسی شدهاند. این مقدار معادل ۴۷ درصد پروتئوم هلیکوباکترپیلوری است. در حال حاضر به کمک روشهای آماری، بانک اطلاعاتی برای برهمکنش پروتئین با پروتئین ایجاد شده است. علاوه بر انتراکتوم باکتریایی، برهمکنشهای پروتئین با پروتئین باکتریوفاژ با استفاده از سنجشهای دو هیبریدی مخمر به خوبی مطالعه شده است. در حدود ۲۷ پروتئین باکتریوفاژ T7 مورد بررسی قرار گرفته است؛ بیشتر این پروتئینها در مورفوژنزیز ویروس باکتریایی نقش دارند.
[۱] Complexosome
[۲] Helicobacter pylori
۱۹۲-فصل هشتم
به خوبی مطالعه شده است. در حدود ۲۷ پروتئین باکتریوفاژ T7 مورد بررسی قرار گرفته است؛ بیشتر این پروتئینها در مورفوژنزیز ویروس باکتریایی نقش دارند.
۵-۶-۸ انتراکتومهای یوکاریوتی
نقشههای برهمکنش پروتئین با پروتئین تعدادی از یوکاریوتها بررسی شده است. انتراکتوم چند موجود زنده مدل مانند مگس، مخمر، نماتد و انسان بهطور وسیع نقشهبرداری شدهاند. مخمر یک مدل ساده از موجود زنده یوکاریوتی است که ژنتیک، بیوشیمی و زیستشناسی مولکولی تثبیت شدهای دارد. مخمر اولین یوکاریوتی است که توالی کامل DNA آن شناسایی و تماماً تفسیر شده است. به همین دلیل درصدد تهیهی نقشه برهمکنش پروتئین با پروتئین مخمر برآمدند تا درک بهتری از شبکه واکنشهای بیوشیمیایی که تعیین کنندهی تمام فعالیتهای سلول (تکوین و رشد) است، بهدست آورند. انواع متفاوتی از روشها برای نشان دادن شبکهی برهمکنش پروتئینها وجود دارد که عبارتاند از: سنجشهای دو هیبریدی مخمر، طیفسنجی، بیوانفورماتیکس و بررسی ژنتیکی. تقریباً ۳۵۰۰۰ برهمکنش پروتئینی در مخمر تخمین زده شده است. تنها بخشی از برهمکنشها به کمک هر کدام از این روشهای فوق مشخص شده است.
مگس سرکه اولین نمونهی موجود زنده پرسلولی است که توالی کامل ژنوم آن در دسترس است. مگس سرکه اولین فرصت برای شناختن تکوین بافت و اندام در پرسلولیها و تمایز در سطح پروتئین و ژنوم را فراهم ساخته است. مدل مگس سرکه مدل خوبی برای شناختن تکوین و بیماری انسانی در سادهترین سطح سازماندهی است. از روش دو هیبرید مخمر برای مطالعهی برهمکنش پروتئین با پروتئین در مگس سرکه استفاده شده است. نقشه مقدماتی بیش از ۴۶۰۰ پروتئین دخیل در بیش از ۴۷۰۰ برهمکنش بهدست آمده است. نقشه انتراکتوم مگس سرکه نیز تصویر شبکهای ارتباط پروتئینها با هم را تأیید میکند. تخمین زده شده است که حدود ۶۵۰۰۰ برهمکنش در انتراکتوم مگس سرکه وجود داشته باشد.
مطالعهی برهمکنش پروتئین با پروتئین برای شناخت تکوین و بیماریها در انسان اهمیت بهسزایی دارد. به محض شناسایی شبکه برهمکنش پروتئینها در موجودات زنده مدل نظیر اشرشیاکلی، مخمر، مگس و نماتد تلاش شد، تا نقشهی برهمکنش پروتئین با پروتئین برای انسان تهیه شود. مطالعات مقدماتی انجام داده شده توسط گروههای مختلف، شبکهای از برهمکنشهای پروتئینی را پیشنهاد کرد. استلزل و همکارانش[۱] بیش از ۳۱۰۰ برهمکنش جدید با دخالت ۱۷۰۵ پروتئین شناسایی کردند. در مطالعهای دیگر با استفاده از دو هیبرید مخمر، گروه ویدال، ۲۸۰۰ برهمکنش شناسایی کردند. نتایج حاصل از روش دو هیبرید مخمر و روش طیفسنجی TAP هفتادوهشت درصد با هم شباهت دارند. نقشهی برهمکنش پروتئین در مقیاس بزرگ با استفاده از روشهای بیوانفورماتیکی فراهم میشود. محققین براساس بررسی دادههای حاصل از دو هیبرید مخمر و روشهای دیگر، یک نقشهی برهمکنش پروتئینی به نام انتراکتوم یکپارچه انسانی[۲] تهیه کردند. انتراکتوم یکپارچه انسانی از ۱۶۰۰۰۰ برهمکنش مجزا با ۱۷۰۰۰ پروتئین منحصر به فرد انسانی تشکیل شده است. در حال حاضر انتراکتوم یکپارچه انسانی به صورت یک نقشهی شبکهای متشکل از حدود ۶۶۵۰۰۰ برهمکنش با تقریباً ۲۵۰۰۰ پروتئین است که توسط ژنوم انسان کد میشود.
۶-۶-۸ STRING
شبکه تعامل پروتئین پروتئین یک بخش مهم در بیوانفورماتیک برای درک سیستمی فرآیندهای سلولی است. چنین شبکههایی را میتوان برای ارزیابی دادههای ژنومیک کارکردی به کار برد. STRING یک بانک اطلاعاتی تحت وب میباشد که دادههای واقعی و پیشگویی شده ای از برهمکنش پروتئین-پروتئین در آن جمع آوری شده است. پایگاه داده STRING شامل اطلاعات از منابع متعددی از جمله دادههای تجربی، دادههای حاصل از روشهای پیش بینی محاسباتی و دادههای مجموعه متون علمی میباشد. دادههای این بانک آزادانه در دسترس است و به طور منظم به روز میشود، آخرین نسخه این بانک در حال حاضر حاوی اطلاعاتی در مورد ۶/۹ میلیون پروتئین از بیش از ۲۰۰۰ موجود زنده است.
[۱] Stelal et al
[۲] Unified human interactome (UniH)
۱۹۳-پروتئومیکس و ایمیونومیکس
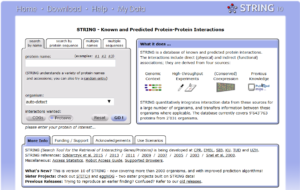
تصویر ۱۸-۸: نمایی از پایگاه STRING.
۷-۸ ایمیونومیکس
Immunomics مطالعه تنظیم سیستم ایمنی بدن و پاسخ به عوامل بیماری زا با استفاده از روش genome-wide میباشد. با ظهور فن آوریهای ژنومی و پروتئوم، دانشمندان قادر به تجسم شبکههای بیولوژیکی و استنباط روابط متقابل بین ژنها و یا پروتئینها میباشند. به تازگی، این فن آوری برای کمک به درک بهتر چگونگی عملکرد سیستم ایمنی بدن و چگونگی تنظیم آن استفاده شده است. حجم وسیعی از دادهها در حوزههای مختلف و بویژه در مباحث علمی ارائه شده است که در منابع اختصاصی ذخیرهسازی شده و حوزهی ایمیونومیکس نیز در برگیرندهی این مطالعات و دادهها میباشد. واژهی ایمیونوم به همهی ژنها وپروتئینهایی اطلاق میشود که در پاسخهای ایمنی شرکت میکنند ولی این واژه شامل ژنها و پروتئینهایی که در سلولهای غیر ایمنی بیان میشوند، نمیباشد. در تعریفی دیگر همهی واکنشهای ایمنی که ناشی از برهم کنشهای بین میزبان و آنتیژنها است، به عنوان برهمکنشهای ایمیونوم شناخته شده و مطالعهی این بر هم کنشها و اجزا شرکت کننده در آن ایمیونومیکس گویند. درک رفتار دینامیک شبکه سیستم ایمنی از طریق بیولوژی سیستمها امکان پذیر است، عنوان کلی Immunoinformatics زمینه جدیدی است که بر پایه استفاده از نرم افزارها در جهت درک کلی این حجم عظیم دادهها شکل گرفته است. ایمونوژنومیک (بررسی ژنهای مرتبط با سیستم ایمنی) و ایمونوپروتئومیک (بررسی پروتئینهای مرتبط با سیستم ایمنی) و یا اصطلاح ایمونومیک immunomics- بررسی همه ژنها و پروتئینهای سهیم در پاسخ ایمنی – مرتبط با این موضوع هستند.
از منادیان ظهور ایمیونومیکس علیزاده و همکارانش در National Cancer Institute هستند که اولین آزمایشها برای بررسی میزان بیان ژنهای سلولهای ایمنی از طریق روش میکروارری cDNA را انجام دادند و همچنین به تجزیه و تحلیل بیان ژنهای سلولهای لنفوسیت B و T در انسان پرداختند. ایمیونومیکس نیز مشابه ژنومیکس و پروتئومیکس از علوم بینرشتهای محسوب شده و از روشهایی با بازده بالا (High throughput) برای درک سیستم ایمنی استفاده میکند. در یک جمع بندی این معلومات، منعکس کنندهی وضعیت کنونی بیماریها وایمنیشناسی انسانی بوده و برای آن دسته از محققینی که به دنبال شناخت مکانیسمهای سیستم ایمنی و بیماریزایی عوامل مختلف هستند منبعی مناسب به حساب میآید. در حقیقت نیاز به مدیریت این علم و منابع در حال گسترش ایمنیشناسی، منجر به ایجاد حوزهی ایمونوانفورماتیک شده است. ایمونوانفورماتیک با استفاده از علوم کامپیوتر اکنون بخشی اساسی از تحقیقات ایمنی شناسی مدرن میباشد. این حوزه مابین علوم کامپیوتری و ایمنیشناسی آزمایشگاهی واقع شده و در حقیقت شاخهای از بیوانفورماتیک میباشد که بر حوزه ی ایمنی شناسی متمرکز شده است . به عبارت دیگر این علم نمایشگر بکارگیری منابع و روشهای محاسباتی برای فهم، تولید، پردازش و گسترش اطلاعات ایمنی شناسی میباشد.
۱۹۴-فصل هشتم
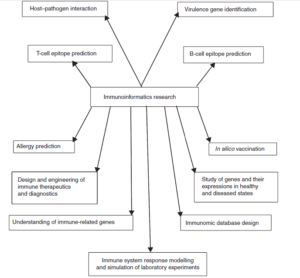
تصویر ۱۹-۸: حوزههای کارکردی ایمونوانفورماتیک.
۱-۷-۸ دفاع اختصاصی
درصورتی که عوامل بیماریزا از سد دفاع غیر اختصاصی همچون پوست و مخاط عبور کنند، با دفاع اختصاصی روبهرو خواهند شد. در این مکانیسم، علاوه بر ماکروفاژها نوعی از گلبولهای سفید به نام لنفوسیتها نقش دارند. لنفوسیتها به طور اختصاصی عمل میکنند، یعنی یک نوع خاصی از عوامل بیگانه را شناسایی و از بین میبرند. لنفوسیتها پس از به وجود آمدن نابالغ هستند و برای کسب ویژگیهای لازم برای شناسایی و مبارزه با میکروبها، باید تکامل یابند. بر اساس محل کسب تکامل، لنفوسیتها را به دو دسته لنفوسیتهای B و لنفوسیتهای T تقسیم میکنند. لنفوسیتهای B در مغز استخوان و لنفوسیتهای T در تیموس تخصص یافتهاند.
لنفوسیتهای بالغ توانایی شناسایی مولکولها و سلولهای خودی را از بیگانه، و نیز مقابله با عوامل بیگانه را به دست میآورند و وارد جریان خون میشوند. لنفوسیتها بر سطح خود دارای گیرندههایی هستند که از لحاظ شکل هندسی مکمل نوع خاصی از آنتیژن (که بر سطح عوامل بیگانه قرار دارد) است. به این ترتیب، هر لنفوسیت، با داشتن نوع خاصی گیرنده، آنتیژن خاصی را شناسایی کرده و از بین میبرد. به همین علت میگوییم که لنفوسیتها به طور اختصاصی عمل میکنند. برخی از لنفوسیتها بین لنف و خون در گردشاند، و برخی دیگر در گرههای لنفی، طحال، لوزهها و آپاندیس جمع میشوند.
۲-۷-۸ ایمنی هومورال
ایمنی هومورال بخشی از دفاع اختصاصی است که به مبارزه با باکتریها و ویروسهای موجود در مایعات بدن میپردازد ودر آن لنفوسیتهای B نقش دارند. لنفوسیتهای B هنگامی که برای نخستین بار به آنتیژنی متصل میشوند، رشد مییابند، تقسیم میشوند و طی تغییراتی به پلاسموسیت و سلولهای B خاطره تبدیل میشوند. پلاسموسیتها پروتئینهایی به نام پادتن ترشح میکنند که در خون محلول هستند. هر نوع پادتن به نوع خاصی آنتیژن متصل میشود و آن را از بین میبرد. نحوهی عمل پادتنها گوناگون است. در بسیاری از موارد پادتن با اتصال به آنتیژنهای سطح عامل بیگانه، از اتصال آن به سایر سلولهای بدن جلوگیری میکند، و موجب میشود میکروب به آسانی توسط ماکروفاژ بلعیده شود. سلولهای B خاطره نیز در بدن در حالت آمادهباش میمانند و درصورت برخورد دوباره با همان آنتیژن، تعداد بیشتری پلاسموسیت و مقدار کمی سلول خاطره تولید میکنند. در نتیجه، پادتن با مقدار و سرعت بیشتر تولید میگردد و مبارزه با شدت بیشتری انجام میشود.
۱۹۵-پروتئومیکس و ایمیونومیکس
۳-۷-۸ ایمنی سلولی
مکانیسم ایمنی سلولی به مبارزه با سلولهای آلوده به ویروس و باکتری، و سلولهای سرطانی میپردازد. در این روش، لنفوسیتهای T نقش دارند. این سلولها نیز، پس از اتصال با آنتیژنی خاص، تکثیر پیدا کرده و انواعی از سلولهای T را به وجود میآورند:
- سلولهای T کشنده : این سلولها توانایی شناسایی و حملهی مستقیم را به سلول آلوده یا سرطانی دارند. آنها با ترشح پروتئینی به نام پرفورین، منافذی را در این سلولها ایجاد میکنند که به مرگ آنها میانجامد.
- سلولهای T کمککننده: فراوانترین نوع لنفوسیتهای T میباشد که به اعمال دستگاه ایمنی کمک میکند. این سلولها، هدف ویروس HIV هستند.
- سلولهای T تضعیفکننده: این سلولها اعمال سلولهای T کشنده و کمککننده را کنترل میکنند و به پاسخ ایمنی خاتمه میدهند و از پاسخهای بیش از حد شدید جلوگیری میکنند.
- سلولهای T خاطره: این سلولها در حالت آمادهباش در بدن میمانند.و طریقه ی مبارزه با ویروس را به نسلهای بعدی انتقال میدهند.
۴-۷-۸ پیش بینی اپیتوپهای سلولهای B و T
ایمنی اختصاصی دارای دو بازوی اصلی است: ایمنی سلولی که مرتبط با لنفوسیتهای T است و ایمنی هومورال که با لنفوسیتهایB ارتباط دارد. در هر دو مورد پاسخ ایمنی از طریق شناسایی قسمت کوچکی از آنتیژن بهنام اپی توپ تحریک میشود. یک اپی توپ قسمتی از یک آنتیژن است که توسط سیستم دفاعی تشخیص داده میشود.یا به شکلی دیگر میتوان گفت اپیتوپ قسمت اختصاصی مولکولهای بزرگ آنتیژن است که آنتیبادی به آن میچسبد. معمولا اپیتوپها کوچک هستند و شامل ۴ تا ۸ رزیدو آمینواسیدی میباشند.
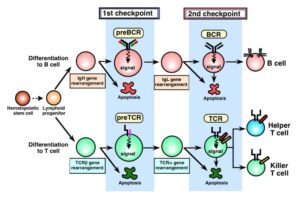
تصویر ۲۰-۸: لنفوسیتهای T و B.
لنفوسیت B
بدن انسان روزانه میلیونها نوع مختلف از سلولهای B را تولید میکند که در خون و سیستم لنفی گردش کرده و نقش نظارت و ایمنی را بازی میکنند. آنها باید کاملا فعال شوند تا آنتیبادی تولید کنند. هر سلول B یک پروتئین گیرندهی
۱۹۶-فصل هشتم
منحصربه فرد (گیرندهی سلول B BCR) در سطح خود دارد که به یک آنتیژن خاص متصل خواهد شد. BCR یک ایمونوگلوبلین متصل به غشا است، و این مولکول است که افتراق سلول B را از سایرانواع لنفوسیتها ممکن میسازد، همچنین این مولکول پروتئین اصلی برای فعال شدن سلول B است. زمانی که سلول B با آنتیژن همجنس خود مواجه میشود و یک پیام اضافی از سلول T کمکی دریافت میکند میتواند به یکی از سلولهای B (سلول B پلاسما و سلول B خاطره) تمایز یابد. اپی توپهایی که توسط لنفوسیت Bشناسایی میگردند وآنتیبادی علیه آنهاتولید میشود، میتواند شاخصهای خطی (Linear) در ساختار اول و یا شاخصهای شکلی (Conformational) در ساختار مولکول باشند.
یک تفاوت عمده بین B سلها و T سلها این است که هرکدام از این لنفوسیتها چگونه آنتیژن خود را میشناسد. B سلها آنتیژن هم جنس خود را به شکل خاموش شناسایی میکنند. آنها با استفاده از BCR یا ایمونوگلوبین متصل به غشا خود آنتیژن آزاد (محلول) در خون یا لنف را شناسایی میکنند. برعکس، T سلها آنتیژن همجنس خود را به یک شکل پردازش شده، به عنوان یک قطعهی پپتیدی که توسط یک مولکول MHC ی سلول ارائه دهندهی آنتیژن به گیرندهی سلول T ارائه شده، شناسایی میکنند.
لنفوسیت T
اپی توپهایی که توسط لنفوسیت Tشناسایی میشوند، توالی اولیه آمینواسیدی در ساختار یک پروتئین هستند. لنفوسیت Tقادر به شناسایی پلی ساکاریدی یا نوکلئیک اسید نیست. برای شناسایی اپی توپها نیازی نیست که شاخص در نواحی بیرونی آنتیژن قرار گرفته باشد زیرا لنفوسیت Tاپی توپها را پس از تجزیه در سلولهای عرضه کننده آنتیژن و تبدیل به قطعات پپتیدی کوچک شناسایی میکند. پپتید آزاد توسط لنفوسیت T شناسایی نمیشود بلکه ترکیب پپتید و مولکول MHCتوسط لنفوسیت Tشناسایی میشود. اپیتوپهای سلول T پپتیدهای خطی کوتاهی هستند که از پروتئینهای آنتیژنیک بریده شدهاند.
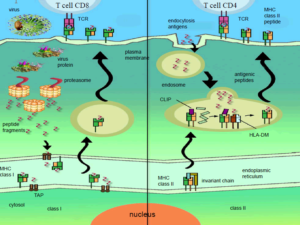
تصویر ۲۱-۸: سلولهای عرضه کننده آنتیژن و شناسایی توسط لنفوسیتهای T. ترکیب پپتید و مولکول MHCتوسط لنفوسیت Tشناسایی میشود.
ارائهی اپیتوپ، وابسته به اتصال MHC و پپتید و همچنین برهم کنشهای گیرندههای سلول T (TCR) میباشد. پروتئینهای MHC چندشکلی بوده و هر یک، به دستهی محدودی از پپتیدها متصل میگردند. دو دستهی اصلی از سلولهای T با بیان پروتئینهای CD8 و CD4 از هم تمایز داده میشوند که هر یک از این سلولها بهترتیب قادر میباشند، اپیتوپهای ارائه شده توسط مولکولهای MHC کلاس ۱یا ۲ را شناسایی کنند.
۱۹۷-پروتئومیکس و ایمیونومیکس
سلولهای T با بیان پروتئینهای CD8 و CD4 از هم تمایز داده میشوند که هر یک از این سلولها بهترتیب قادر میباشند، اپیتوپهای ارائه شده توسط مولکولهای MHC کلاس ۱یا ۲ را شناسایی کنند.
سلولهایی که پپتیدهای متصل به MHC را عرضه میکنند، سلولهای عرضه کننده آنتی ژن (Antigen- Presnting Cells) یابه اختصار APC نامیده میشوند. این سلولها آنتی ژنها را طی مرحله شناسایی پاسخهای ایمنی به سلولهای T بیتجربه عرضه میکنند تا پاسخهای ایمنی شروع شود. همچنین عرضه آنتی ژن به سلولهای T تمایز یافته نیز بر عهده این سلولها است. بنابر این APCها، هم القاء کننده و هم هدف سلولهایT هستند. سلولهای T فقط زمانی آنتی ژنهای پپتیدی بیگانه را شناسایی میکنند و به آنها پاسخ میدهند که در سطح APCها واقع شده باشند. در حالی که سلولهای B و آنتی بادیهای ترشح شده توسط آنها به آنتی ژنهای محلول موجود در مایعات بدن و نیز آنتی ژنهای موجود در سطح سلولها پاسخ میدهند. دلیل این تفاوت نیز آنست که همانطور که ذکر شد سلولهای T فقط آن نوع پپتیدهایی را شناسایی میکنند و به آنها پاسخ میدهند که به مولکولهای MHC متصل شده باشند و مولکولهای MHC نیز پروتئینهای غشایی سر تا سری موجود در سطح APCها هستند. سلولهایT هر فردی فقط زمانی آنتی ژنهای پپتیدی بیگانه را شناسایی میکنند که به مولکولهای MHC همان فرد متصل باشند.
دانش مربوط به پاسخهای به واسطهی سلولهای B و T، با سرعت قابل توجهی افزایش یافته است. پاسخهای ایمنی به انواع سلولهای سرطانی و عوامل بیماریزا نیز با روشهای مختلف در حال شناسایی هستند. در حالی که این عوامل یکی پس از دیگری در متون علمی تعریف میگردند، جمعآوری چنین دادههایی در قالب پایگاهدادهها و نیز فرآهم آوردن ابزارهای محاسباتی برای کمک به تفسیر آنها از ارزش بالایی برخوردار خواهد بود. پایگاههای اطلاعاتی مربوط به دانستههای اپیتوپی، ابزارهای بیوانفورماتیک والگوریتمهای پیشبینی، به فهم ساختار و توالی اسیدآمینههای موجود در اپیتوپها کمک میکنند. چنین دانشی برای مطالعات ایمنیشناسی پایه، تشخیص، درمان انواع بیماریها و همچنین تحقیقات مربوط به واکسن اساسی خواهد بود
تعدادی از بانکهای مهم در زمینه اپی توپهای قابل تشخیص توسط سلولهای B به نامهای CED، IEDB و… وجود دارند که تعدادی از این بانکهای مفید به همراه آدرس آنها در جدول ۲-۸ معرفی شدهاند.
جدول ۲-۸: تعدادی از بانکهای مهم در زمینه اپی توپهای قابل تشخیص توسط سلولهای B.
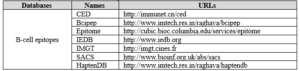
Bcipep یک دیتا بیس در زمینه اپی توپهای قابل تشخیص توسط سلولهای B میباشد که دادههای آن حاصل فعالیتهای آزمایشگاهی میباشد و دادههای آن تجربی میباشند. همچنین در این پایگاه ابزاری برای تعیین نقشه اپی توپها بر روی توالی آنتیژنها در اختیار قرار داده شده است. نمایی از این پایگاه را در زیر میبینید.
۱۹۸-فصل هشتم

تصویر ۲۲-۸: نمایی از پایگاه Bcipep.
IEDB (The Immune Epitope Database) این بانک یکی از کاملترین بانکهای اپیتوپ میباشد که اطلاعات مربوط به توالی اپی توپ،آنتی ژن مرجع و موجودی که توالی ازآن برگرفته شده را ارائه میدهد. نمایی از این پایگاه را در تصویر ۲۳-۸ میبینید.
تصویر ۲۴-۸: نمایی از پایگاه IEDB.
تعدادی از بانکهای مهم در زمینه اپی توپهای قابل تشخیص توسط سلولهای T به نامهای JenPep، FRED و… وجود دارند که تعدادی از این بانکهای مفید به همراه آدرس آنها در جدول ۳-۸ معرفی شدهاند.
جدول ۳-۸: تعدادی از بانکهای مهم در زمینه اپی توپهای قابل تشخیص توسط سلولهای T.

SYFPEITHI (A DATABASE OF MHC LIGANDS AND PEPTIDE MOTIFS) امکان بررسی دقیق اپی توپهایی که به MHC متصل میشوند و بخشهای لنگر وکمکی اختصاصی MHC را فراهم میکند. نمایی از این
۱۹۹-پروتئومیکس و ایمیونومیکس
پایگاه را در تصویر ۲۴-۸ میبینید که میتواند با استفاده از قسمتهای مربوطه اپیتوپهای توالی مورد نظر خود را شناسایی کنید.
تصویر ۲۴-۸: نمایی از پایگاه SYFPEITHI.
FRED یک چارچوب برای تشخیص اپی توپ سلول Tارائه میدهد و بانکی در زمینه اپی توپهای قابل تشخیص توسط سلولهای T میباشد. نمایی از این پایگاه را در تصویر ۲۵-۸ میبینید.

تصویر ۲۵-۸: نمایی از پایگاه FRED.
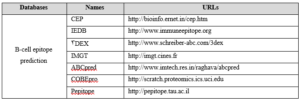
بانکهایی که تا اینجا معرفی شدند به اپی توپهای قابل تشخیص میپردازند اما در ادامه با بانکهای اطلاعاتی آشنا میشوید که مربوط به پیشبینی اپیتوپهای سلولهای B و T هستند و به این صورت عمل میکنند که یک توالی از شما میگیرند و اپی توپهای آن توالی را پیش بینی میکنند. در جدول ۴-۸ زیر تعدادی از بانکهای مهم در زمینه پیش گویی اپی توپهای سلولهای B معرفی شدهاند.
جدول ۴-۸: تعدادی از بانکهای مهم در زمینه پیش گویی اپی توپهای سلولهای B.
۲۰۰-فصل هشتم
بانکهای مهمی همچون TEPITOPE، Pcleavage و … در زمینه پیش گویی اپی توپهای سلولهای Tوجود دارند که در جدول ۵-۸ تعدادی از بانکهای مهم در این زمینه معرفی شدهاند.
جدول ۵-۸: بانکهایی در زمینه پیش گویی اپی توپهای سلولهای T.

۵-۷-۸ کاربردهای ایمونوانفورماتیک در بررسی تکامل ژنها و پروتئینهای سیستم ایمنی
برای مشخص شدن روند تکامل سیستم ایمنی پایگاههایی ایجاد شدهاند همچون پایگاه اطلاعاتی با عنوان IMMTREE که برای نمایش درختهای تکاملی پروتئینهای سیستم ایمنی انسان ایجاد کردهاند. در پایگاه Immunome تعداد ۸۴۷ ژن و پروتئین بر اساس عملکرد، دومینهای پروتئینی و از نظر Ontology شرح داده شدهاند.
جدول ۶-۸: برخی از پایگاههایی که در زمینه روند تکامل سیستم ایمنی کار میکنند.

۲۰۱-پروتئومیکس و ایمیونومیکس
حوزهی ایمنوانفورماتیک با سرعت در حال توسعه میباشد و هماکنون حدودا در تمامی بخشهای مطالعات ایمنیشناسی کاربرد دارد. ابزارهای مختلفی در این حوزه ایجاد شده است و به سرعت در حال رشد میباشند اما هنوز هنوز نیاز به همکاریهای بیشتر بین رشته ای وجود دارد تا بتوانیم به اهدافی از جمله رسیدن به یک سیستم ایمنی مجازی دست پیدا کنیم.
۶-۷-۸ آلرژیزاها
آلِرژی یا حَسّاسیَت، (به انگلیسی: allergy) واکنش افراطی سیستم ایمنی بدن نسبت به عوامل گوناگون است. کسانی که دچار حساسیت هستند، دارای دستگاه ایمنی فوق هوشیار هستند که نسبت به مواد ظاهراً بی ضرر موجود در محل زندگیشان، واکنشی بیش از حد معمول نشان میدهند. برای مثال گرده گیاهان، میتواند سیستم ایمنی شخص آلرژیک را طوری تحریک کند که گویی با یک خطر جدی روبرو شدهاست. حساسیت یک مشکل بسیار شایع است و تقریباً از هر ده نفر، دو نفر به نوعی از آن مبتلا هستند.
با توجه به رشد روز افزون ابتلا به آلرژی در کشورهای توسعه یافته و یا در حال توسعه باعث بیشتر شدن اهمیت موضوع آلرژی شده است و باعث افزایش روزافزون تحقیقات در این زمینه شده وحجم بالایی از اطلاعات را نیز ایجاد کرده است. این روند، استفاده از رویکردهای بیوانفورماتیک برای سازماندهی و سهولت درتفسیر این اطلاعات را اجتناب ناپذیر کرده است.
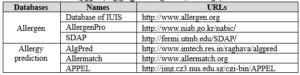
بانکهای اطلاعاتی مربوط به آلرژی در حال گسترش میباشند که برخی از آنها مثل SDAP به بانکی در زمینه آلرژنها تبدیل شده است و یا بانکی به نام APPEL به پیش گویی آلرژنها میپردازد.
جدول ۷-۸: بانکهای اطلاعاتی مربوط به آلرژی.
۷-۷-۸ In-silico واکسیناسیون
واکسن سوسپانسیونی است از ریزاندامگانهای کشته یا ضعیفشدهی ویروس یا باکتری یا پروتئینهای آنتیژنیک بهدستآمده از آنها که برای پیشگیری یا بهبود یا درمان بیماریهای عفونی تجویز میشود. با توجه به این که پروژههای ژنوم بسیاری از میکروبها به اتمام رسیده است و اطلاعات زیادی در مورد ژنوم و پروتئینهای مختلف میکروبها وجود دارد محققین قسمتهایی از ژنوم میکروبها را که منجر به تحریک سیتم ایمنی میشوند و یا به عبارت دیگر اپیتوپها را بجای روشهای کاوش در in vitro از ابزارهای ایمنوانفورماتیک در In-silico برای بررسی این موارد استفاده میکنند و سپس در in vitro دادهها را تایید میکنند. برای مثال پایگاه DyNAVacs با هدف طراحی DNA واکسنهای بهینه و کارآمد ایجاد شده که خدماتی مانند بهینهسازی کدونها، مهندسی موتیفهای CpG، وارد کردن توالیهای مثل کوزاک و انتخاب نوع ناقل را ارائه میدهد. و یا پایگاه NERVE بهترین نامزدهای واکسن را معرفی میکند. برخی از پایگاههای مربوطه به واکسیناسیون In-silico و پیوندهای اینترنتی آنها را در جدول ۸-۸ وجود دارد.
جدول ۸-۸: برخی از پایگاههای مربوطه به واکسیناسیون In-silico.
